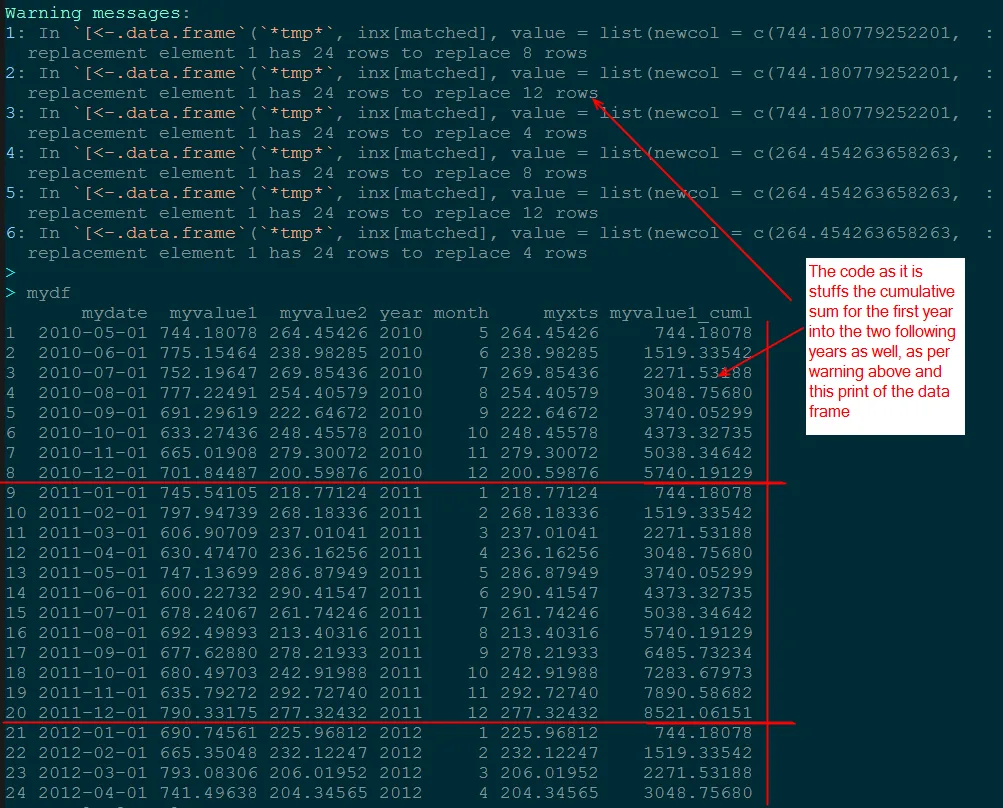
与此问题相关,但出于清晰起见,我决定提出另一个问题。简而言之,我正在使用ddply来累加三年中每个值的总和。我的代码从第一年获取数据并在该列的第二年和第三年重复。我猜测每个1年块都被复制到整个列中,但我不知道为什么会这样。
问:如何在指定列的正确行中获取每年的累积和?
[编辑:for循环(或类似的东西)非常重要,因为最终我想通过列名列表自动计算新列,而不是手动计算每个新列。循环遍历列名列表。]
我经常使用ddply和cumsum组合,所以突然出现问题让我感到非常恼火。
[编辑:此代码已更新为我解决方案,该解决方案基于下面@Chase的答案]
require(lubridate)
require(plyr)
require(xts)
require(reshape)
require(reshape2)
set.seed(12345)
# create dummy time series data
monthsback <- 24
startdate <- as.Date(paste(year(now()),month(now()),"1",sep = "-")) - months(monthsback)
mydf <- data.frame(mydate = seq(as.Date(startdate), by = "month", length.out = monthsback),
myvalue1 = runif(monthsback, min = 600, max = 800),
myvalue2 = runif(monthsback, min = 1900, max = 2400),
myvalue3 = runif(monthsback, min = 50, max = 80),
myvalue4 = runif(monthsback, min = 200, max = 300))
mydf$year <- as.numeric(format(as.Date(mydf$mydate), format="%Y"))
mydf$month <- as.numeric(format(as.Date(mydf$mydate), format="%m"))
# Select columns to process
newcolnames <- c('myvalue1','myvalue4','myvalue2')
# melt n' cast
mydf.m <- mydf[,c('mydate','year',newcolnames)]
mydf.m <- melt(mydf.m, measure.vars = newcolnames)
mydf.m <- ddply(mydf.m, c("year", "variable"), transform, newcol = cumsum(value))
mydf.m <- dcast(mydate ~ variable, data = mydf.m, value.var = "newcol")
colnames(mydf.m) <- c('mydate',paste(newcolnames, "_cum", sep = ""))
mydf <- merge(mydf, mydf.m, by = 'mydate', all = FALSE)
mydf
ddply和transform。然而昨天我发现我需要对12个数据系列进行操作,这让我得出结论,我的当前方法直接编码每个值是不可扩展的,需要重新思考。for循环是我尝试自动化构建这些年度累计总数列(以及其他常见计算)的方法。 - SlowLearnerddply在“年份”和“变量”上进行分组计算,最后再转换回宽格式。 - Chasefor循环... 我已经尝试过mydf <- melt(mydf, id = c('mydate','year','month')) mydf$newcol <- 1 mydf <- ddply(mydf, .(year, variable), transform, newcol = cumsum(value)) colnames(mydf)[colnames(mydf)=="newcol"] <- paste(variable, "_cuml", sep = "", collapse = "") mydf <- cast(mydf, mydate ~ variable + newcol)这个方法似乎可以解决问题,但我无法确定最终的转换以将newcol返回到宽格式。您能帮忙吗? - SlowLearner