我还可以提供另一种解决方案。
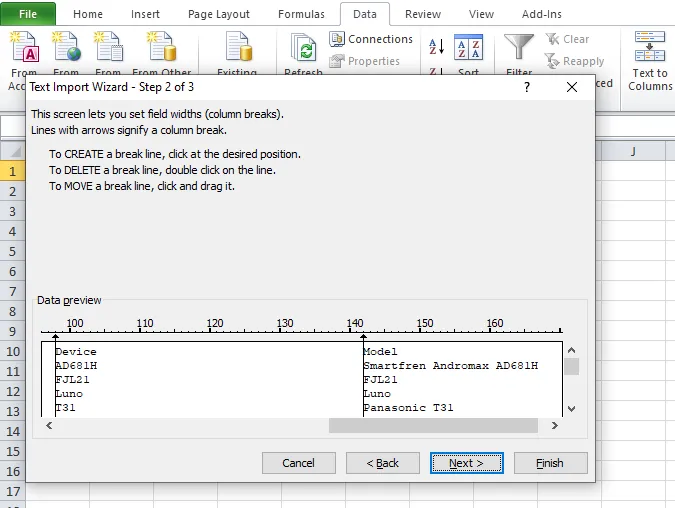
虽然在这种情况下,使用“pdftotext”方法的工作量合理,但有些情况下每一页的列宽可能不同(正如您所展示的PDF文件)。在这种情况下,不太为人知但相当酷的免费开源软件
Tabula-Extractor是最佳选择。
我自己正在使用直接从GitHub检出的版本:
$ cd $HOME ; mkdir svn-stuff ; cd svn-stuff
$ git clone https://github.com/tabulapdf/tabula-extractor.git git.tabula-extractor
我写了一个非常简单的封装脚本,就像这样:
$ cat ~/bin/tabulaextr
cd ${HOME}/svn-stuff/git.tabula-extractor/bin
./tabula $@
既然~/bin/在我的$PATH中,我只需要运行
$ tabulaextr --pages all \
$(pwd)/DAC06E7D1302B790429AF6E84696FCFAB20B.pdf \
| tee my.csv
从所有页面提取所有表格并将它们转换为单个CSV文件。
前10行(共8727行)的CSV如下所示:
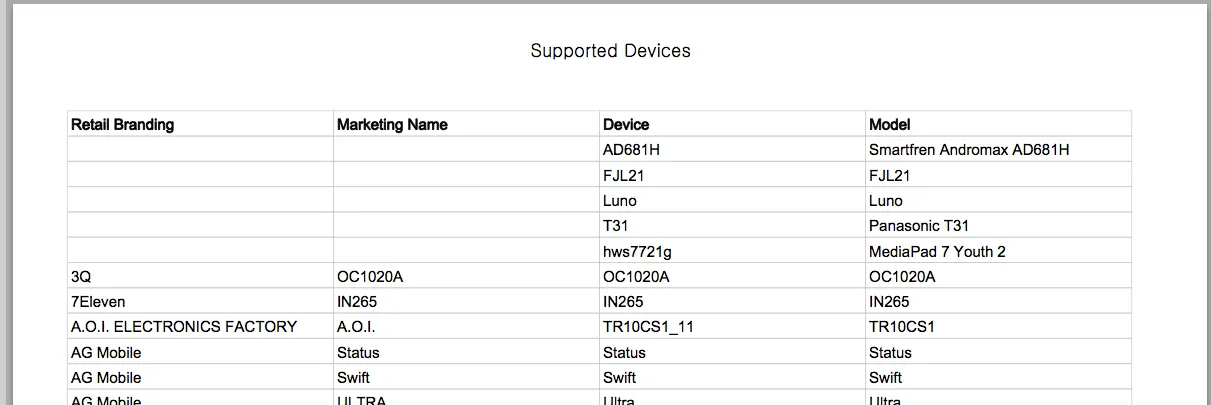
$ head DAC06E7D1302B790429AF6E84696FCFAB20B.csv
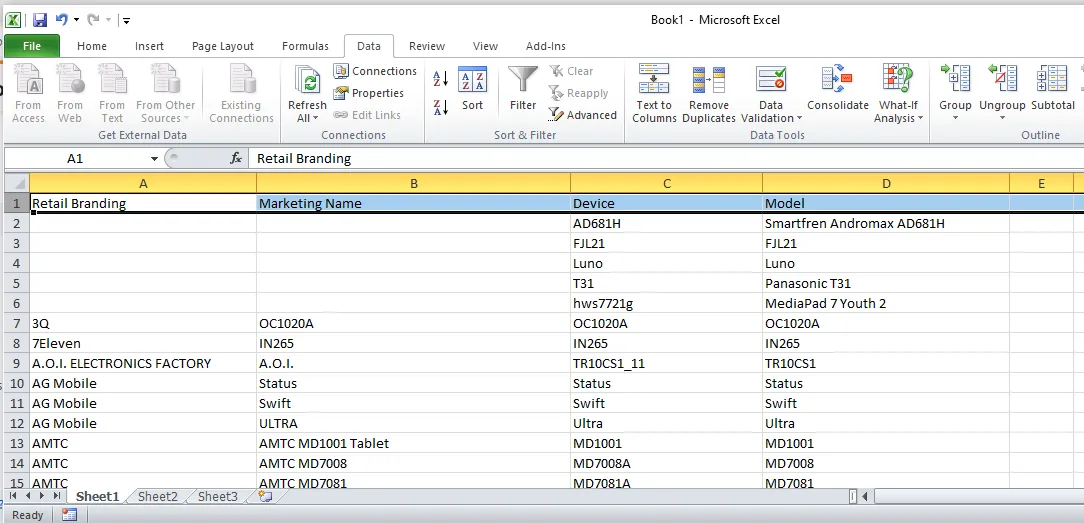
Retail Branding,Marketing Name,Device,Model
"","",AD681H,Smartfren Andromax AD681H
"","",FJL21,FJL21
"","",Luno,Luno
"","",T31,Panasonic T31
"","",hws7721g,MediaPad 7 Youth 2
3Q,OC1020A,OC1020A,OC1020A
7Eleven,IN265,IN265,IN265
A.O.I. ELECTRONICS FACTORY,A.O.I.,TR10CS1_11,TR10CS1
AG Mobile,Status,Status,Status
在原始的PDF中看起来是这样的:
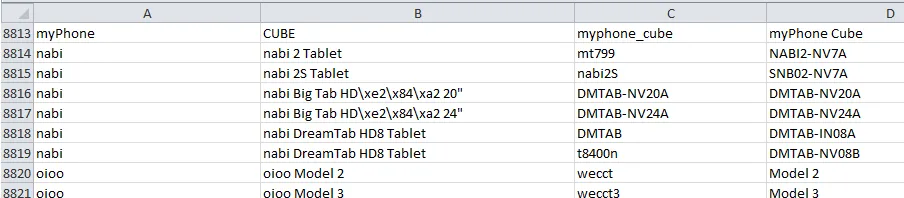
甚至在最后一页,第293页,也有这些行:
nabi,"nabi Big Tab HD\xe2\x84\xa2 20""",DMTAB-NV20A,DMTAB-NV20A
nabi,"nabi Big Tab HD\xe2\x84\xa2 24""",DMTAB-NV24A,DMTAB-NV24A
在PDF页面上看起来像这样:

TabulaPDF和Tabula-Extractor在这类工作中非常非常棒!
更新
这里有一个 ASCiinema 屏幕录像(你也可以通过 下载 并使用 asciinema 命令行工具在 Linux/MacOSX/Unix 终端本地重新播放),主角是 tabula-extractor: