我有一个遵循以下格式的数据集:
data =[[[1, 0, 1000], [2, 1000, 2000]],
[[1, 0, 1500], [2, 1500, 2500], [2, 2500, 4000]]]
var1 = [10.0, 20.0]
var2 = ['ref1','ref2']
我想将其转换为数据框:
dic = {'var1': var1, 'var2': var2, 'data': data}
import Pandas as pd
pd.DataFrame(dic)
结果如下:
结果:
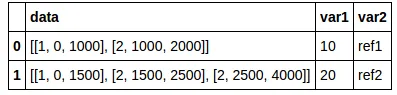
然而,我试图得到像这样的东西:
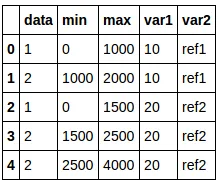
我一直在尝试将字典/列表展开,但没有成功:
pd.DataFrame([[col1, col2] for col1, d in dic.items() for col2 in d])
查看结果:

列表的不同大小使得“解包”变得更加复杂。我不确定 pandas 是否能够处理这个问题,或者需要在导入到 pandas 之前处理。
var1。 - chrisaycockzip中应该是var1和var2而不是两次var1。我已经修复了这个问题。 - Mike Müller