Posting more utility code
see github: https://gist.github.com/1233012#file_new.cpp
This is basically an much better approach to generating all possible permutations based on much simpler approach (therefore I had no real reason to post it before: As it stands right now, it doesn't do anything more than the python code).
I decided to share it anyways, as you might be able to get some profit out of this as the basis for an eventual solution.
Pro:
- much faster
- smarter algorithm (leverages STL and maths :))
- instruction optimization
- storage optimization
- generic problem model
- model and algorithmic ideas can be used as basis for proper algorithm
- basis for a good OpenMP parallelization (n-way, for n rows) designed-in (but not fleshed out)
Contra:
- The code is much more efficient at the cost of flexibility: adapting the code to build in logic about the constraints and cost heuristics would be much easier with the more step-by-step Python approach
All in all I feel that my C++ code could be a big win IFF it turns out that Simulated Annealing is appropriate given the cost function(s); The approach taken in the code would give
- a highly efficient storage model
- a highly efficient way to generate random / closely related new grid configurations
- convenient display functions
Mandatory (abritrary...) benchmark data point (comparison to the python version:)
a b c d e
f g h i j
k l m n o
p q r s t
Result: 207360000
real 0m13.016s
user 0m13.000s
sys 0m0.010s
到目前为止,我们得到了以下内容:
从描述中我了解到你有一个基本的图形,如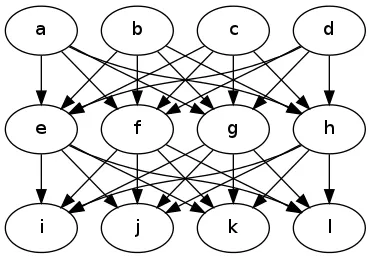
必须构建一条访问网格中所有节点的路径 (哈密顿回路)。
额外的约束是后续节点必须从下一个rank中取出 (a-d、e-h、i-l 是三个rank;一旦访问了最后一个rank的节点,路径必须继续与第一个rank中的任何未访问节点连接)
边缘具有权重,因为它们具有相关的成本。然而,权重函数对于图算法来说不是传统的,因为成本取决于整个路径,而不仅仅是每个边缘的端点。
根据这些信息,我认为我们处于“全覆盖”问题的领域中(需要A*算法,最著名的是Knuths Dancing Links论文)。
具体而言,如果没有更多的信息(路径的等价性、成本函数的特定属性),则获得满足约束条件的“最便宜”的哈密顿路径的最佳已知算法将是:
- 生成所有可能的这样的路径
- 计算每个实际成本函数
- 选择最小成本路径
因此,我已经开始编写了一个非常愚蠢的暴力生成器,可以在一个通用的NxM网格中生成所有可能的唯一路径。
宇宙的终结
对于3×4的示例网格,输出结果为4!3=13824种可能的路径...将其推广到6×48列,得到6!48=1.4×10137种可能性。很明显,如果没有进一步优化,这个问题是难以处理的(NP难或其他什么——我从来没有记住过那些微妙的定义)。
运行时间的爆炸声震耳欲聋:
- 3×4(测量)需要大约0.175秒
- 4×5(测量)需要大约6分5秒(在快速机器上无输出运行并在PyPy 1.6下运行)
- 5×6需要大约10年9个月...
在48x6的情况下,我们将会看到...什么...8.3x10107 年(请仔细阅读)
无论如何,这是Python代码(所有预设为2×3网格)
ROWS = 2
COLS = 3
def cell(r,c):
index = COLS*(r) + c
def baseN(num,b,numerals="abcdefghijklmnopqrstuvwxyz"):
return ((num == 0) and numerals[0]) or (baseN(num // b, b, numerals).lstrip(numerals[0]) + numerals[num % b])
return baseN(index, 26)
ORIGIN = cell(0,0)
def debug(t): pass;
def dump(grid): print("\n".join(map(str, grid)))
def print_path(path):
print " -> ".join(map(str, path))
def bruteforce_hamiltonians(grid, whenfound):
def inner(grid, whenfound, partial):
cols = len(grid[-1])
if cols<1:
whenfound(partial)
pass
else:
for i,rank in enumerate(grid):
if len(rank)<cols: continue
for ci,cell in enumerate(rank):
partial.append(cell)
grid[i] = rank[:ci]+rank[ci+1:]
inner(grid, whenfound, partial)
grid[i] = rank
partial.pop()
break
pass
inner(grid, whenfound, [])
grid = [ [ cell(c,r) for r in range(COLS) ] for c in range(ROWS) ]
dump(grid)
bruteforce_hamiltonians(grid, print_path)