感谢Google和Stack Overflow的帮助,我认为我已经理解了常规HTTP流水线和HTTP多路复用(例如使用SPDY)之间的区别,因此我制作了下面的图表,以展示基于三个常规HTTP请求的流水线和多路复用之间的差异。
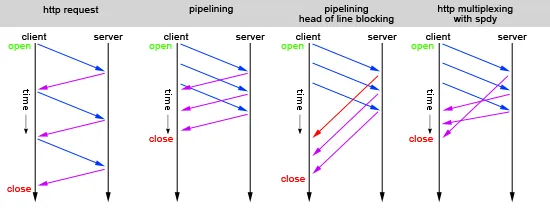
我的两个问题是:
- 这张图片正确吗?
- 如果流水线处理没有头阻塞问题,它是否像HTTP多路复用一样快?或者我错过了其他的区别?
我的两个问题是:
这并不是错误的,但它省略了一个重要的方面。HTTP要求在任何其他请求继续之前,必须传递整个响应。从图中显示的意义上来说,使用SPDY我们最终可以打破“先来先服务”(head of line)的要求,并在响应可用时立即传递响应。然而,我们也不必等待任何请求完全完成。
想象一下两个请求,都有几千字节大小:每个请求将有多个数据包,称为[r1p1,r1p2]和[r2p1,r2p2]。HTTP要求pN以确切的顺序到达。另一方面,SPDY允许我们采用以下方式:[r2p1,r1p1,r1p2,r2p2]。
值得一提的是,使用SPDY,我们可以使用请求优先级提示服务器应该优先处理哪些请求,即使它晚些到达电线(还有其他半打特色)。