我希望使用我的PyMC3 LR模型,在新数据可用时获得预测变量y值的80% HPD范围。因此,对于原始数据集中不存在的新x值,外推出y的可信分布值。
模型:
在进行烧伤后,我从后验分布中取样并获得HPD。
with pm.Model() as model_tlr:
alpha = pm.Normal('alpha', mu=0, sd=10)
beta = pm.Normal('beta', mu=0, sd=10)
epsilon = pm.Uniform('epsilon', 0, 25)
nu = pm.Deterministic('nu', pm.Exponential('nu_', 1/29) + 1)
mu = pm.Deterministic('mu', alpha + beta * x)
yl = pm.StudentT('yl', mu=mu, sd=epsilon, nu=nu, observed=y)
trace_tlr = pm.sample(50000, njobs=3)
在进行烧伤后,我从后验分布中取样并获得HPD。
ppc_tlr = pm.sample_ppc(btrace_tlr, samples=10000, model=model_tlr)
ys = ppc_tlr['yl']
y_hpd = pm.stats.hpd(ys, alpha=0.2)
这对于可视化中心趋势周围的HPD(使用fill_between)非常有用。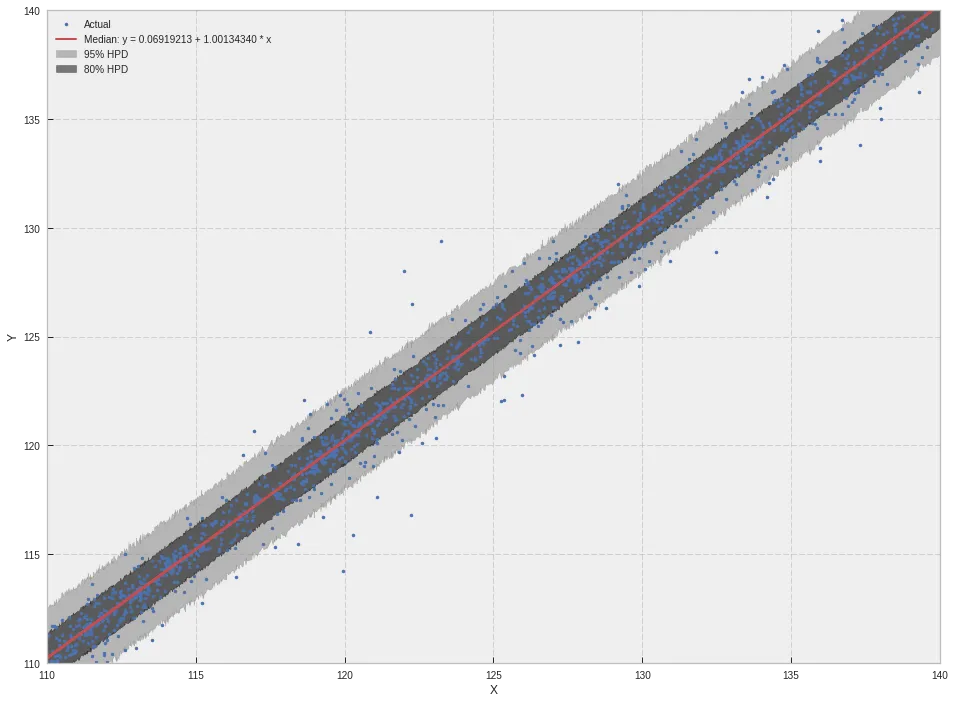
但是,我现在想使用模型来获取x=126.2时y的HPD(例如),而初始数据集没有包含观察到的x=126.2。
我理解从后验分布进行抽样的方式是,对于数据集中每个可用的x值,都有10k个样本,因此对于x=126.2,由于没有观察到,ys中不存在相应的抽样。
基本上,是否有一种方法可以使用我的模型从一个预测值x=126.2(在构建模型之后才变得可用)获得可信区间值(基于模型)的分布?如果有,怎么做?
谢谢
编辑:
找到SO帖子提到的内容
正在开发的功能(很可能最终会添加到pymc3中),可以预测新数据的后验分布。
这个存在吗?