斐波那契堆数据结构的名称中包含“斐波那契”一词,但数据结构中似乎没有使用斐波那契数。根据维基百科文章:
斐波那契堆的名称来自斐波那契数,在运行时间分析中使用。
这些斐波那契数是如何在斐波那契堆中出现的?
斐波那契堆的名称来自斐波那契数,在运行时间分析中使用。
这些斐波那契数是如何在斐波那契堆中出现的?
Smallest possible order 0 tree: *
最小可能的一阶树至少需要一个带有子节点的节点。我们能够创建的最小可能的子节点是一个只有一个子树为最小零阶树的单个节点,该树如下所示:
Smallest possible order 1 tree: *
|
*
那么二阶最小的树是什么样子呢?这就变得有趣了。这棵树肯定要有两个子节点,它将由两棵一阶树合并而成。因此,这棵树最初会有两个子节点——一棵零阶树和一棵一阶树。但请记住——我们可以在合并树后从中切除子节点!在这种情况下,如果我们切除一阶树的子节点,我们将得到一棵有两个子节点的树,它们都是零阶树:
Smallest possible order 2 tree: *
/ \
* *
那么3阶的情况呢?和之前一样,这个树是由两个2阶树合并而成的。然后我们会尽可能地剪掉这个3阶树的子树。当它被创建时,它有2、1、0阶的子树。我们无法从0阶子树中剪切,但可以从2阶和1阶子树中各剪切一个子节点。这样,我们就得到了一个具有三个子节点的树,其中一个是1阶,另外两个是2阶:
Smallest possible order 3 tree: *
/|\
* * *
|
*
NC(0) = 1
NC(1) = 2
NC(n + 2) = NC(n) + NC(n - 1) + ... + NC(1) + NC(0) + NC(0) + 1
NC(0) = 1
NC(1) = 2
NC(2) = NC(0) + NC(0) + 1 = 3
NC(3) = NC(1) + NC(0) + NC(0) + 1 = 5
NC(4) = NC(2) + NC(1) + NC(0) + NC(0) + 1 = 8
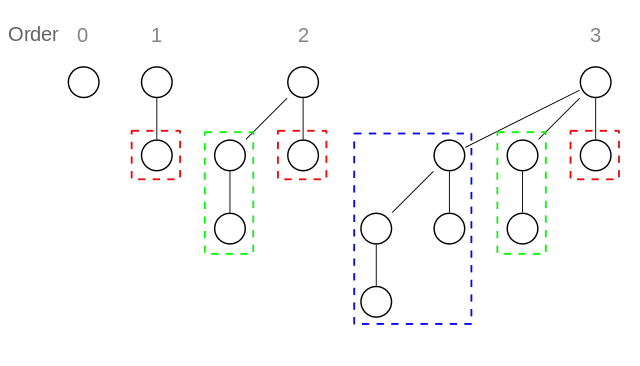
"合并"过程的细节并不重要,但本质上它基本上是将同一度数的树联合在一起,直到所有树都具有不同的度数(尝试使用酷炫的可视化工具来查看这些树是如何构建的)。由于您可以将任何n写成2的确切幂的和,因此很容易想象对于任何n,Fibonacci堆的合并树会是什么样子。
到目前为止,我们仍然没有看到斐波那契数列的直接联系。它们实际上出现在非常特殊的情况下,这也是为什么斐波那契堆可以为DECREASE-KEY操作提供O(1)时间的关键所在。当我们减少一个键时,如果新键仍然大于父键,则我们不需要做任何其他事情,因为最小堆属性没有被违反。但如果不是这样,我们不能让较小的子节点埋藏在更大的父节点下面,因此我们需要将其子树剪切出来,并将其制作成新树。显然,我们不能每次删除都这样做,否则我们最终会得到树太高且不再具有指数项的树,这意味着提取操作不再具有O(log n)时间。所以问题是我们可以设置什么规则,使树仍然具有指数项的高度?聪明的想法是这样的: