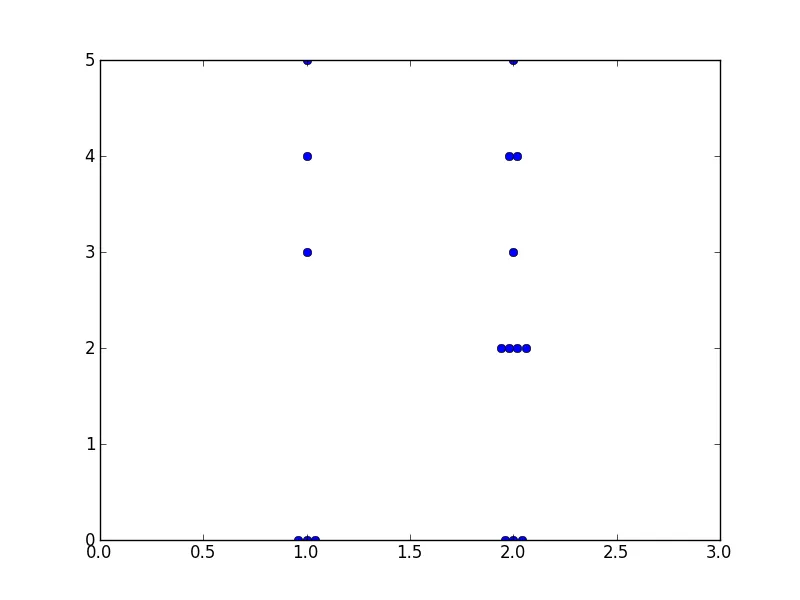
在使用
我希望每个"0"数据点的
在R(
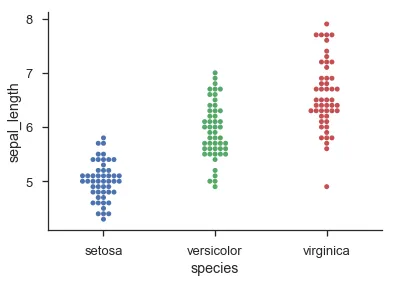
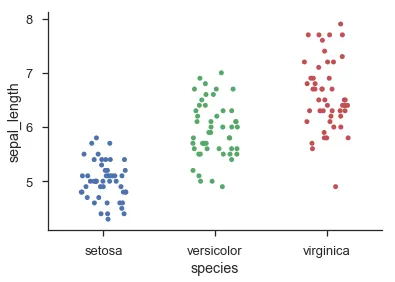
编辑:为了澄清,我想要的实际上是R中的"beeswarm"图,而
编辑:补充说明,Seaborn的Swarmplot(在0.7版本中引入)是我想要的一个很好的实现。
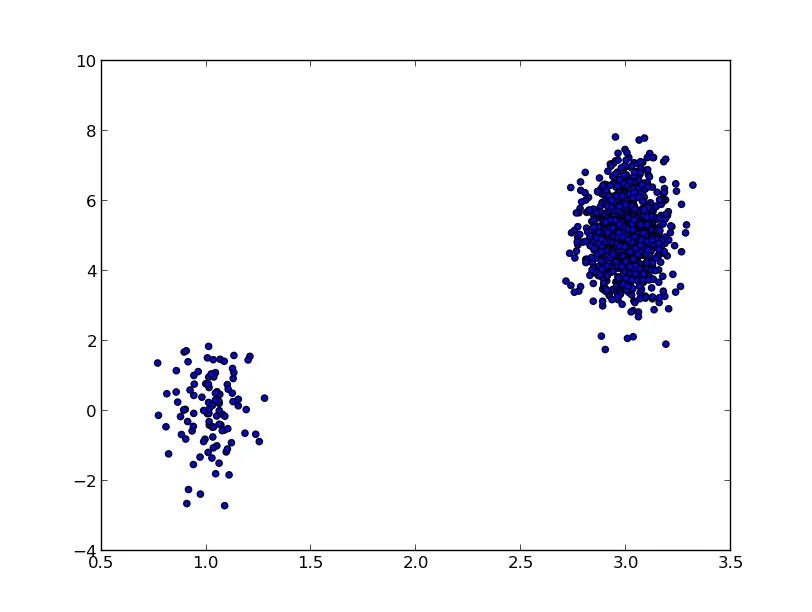
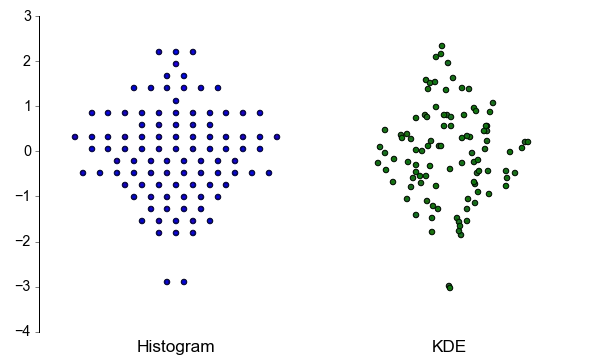
matplotlib绘制点图时,我希望将重叠的数据点进行偏移,以保持它们全部可见。例如,如果我有:CategoryA: 0,0,3,0,5
CategoryB: 5,10,5,5,10
我希望每个"0"数据点的
CategoryA能够并排显示,而不是重叠在一起,同时仍然与CategoryB保持区分。在R(
ggplot2)中,有一个"jitter"选项可以实现这一点。在matplotlib中是否有类似的选项,或者是否有其他方法可以达到类似的效果?编辑:为了澄清,我想要的实际上是R中的"beeswarm"图,而
pybeeswarm是一个早期但有用的matplotlib/Python版本的起点。编辑:补充说明,Seaborn的Swarmplot(在0.7版本中引入)是我想要的一个很好的实现。