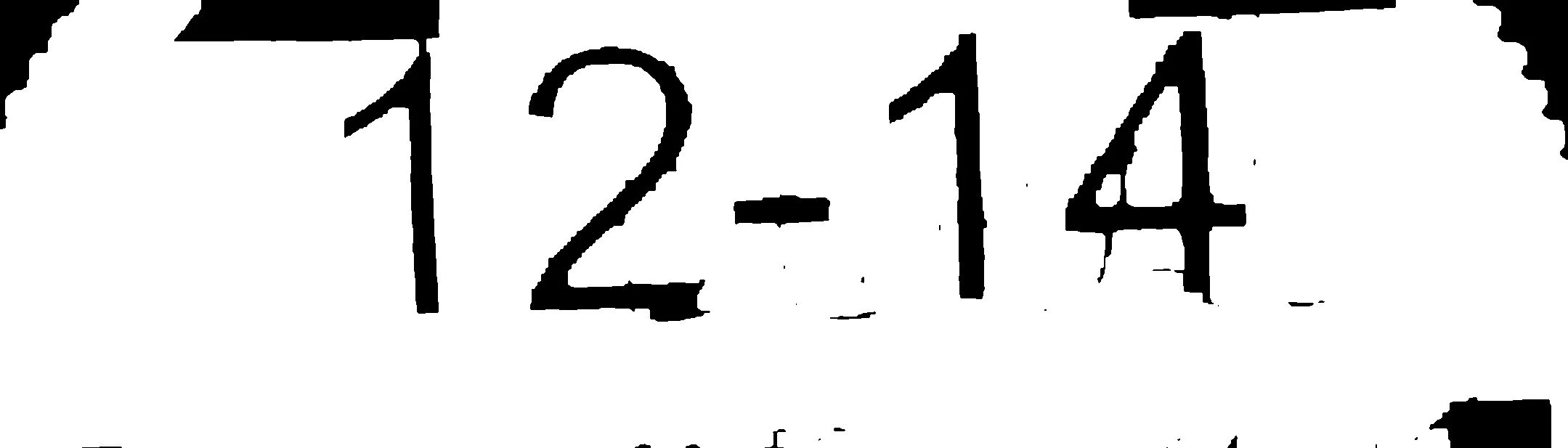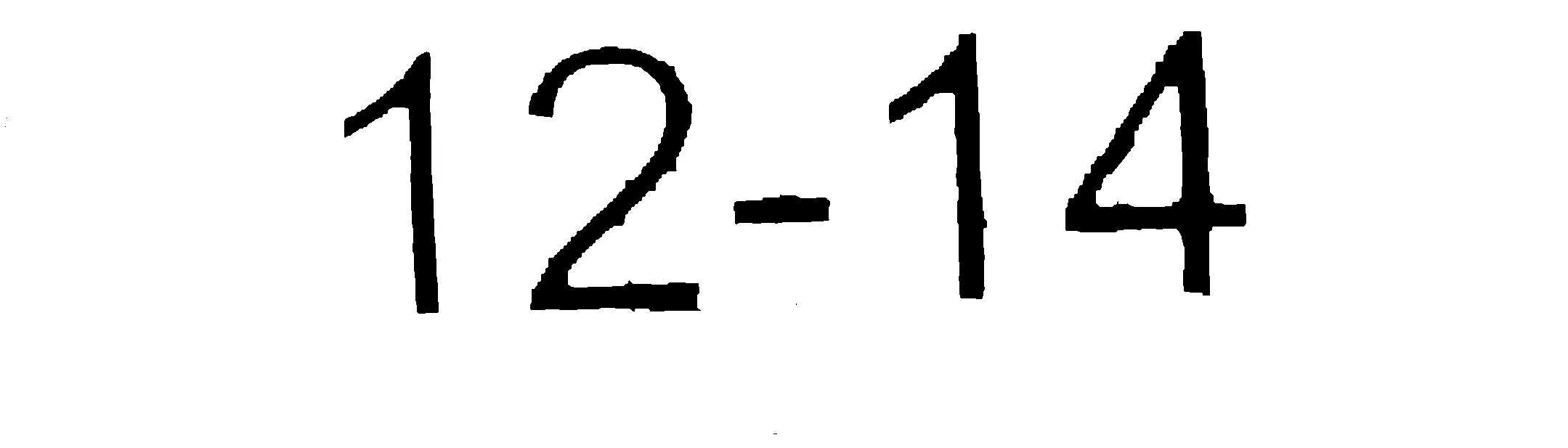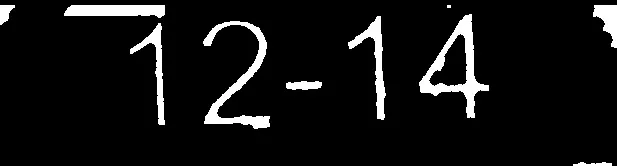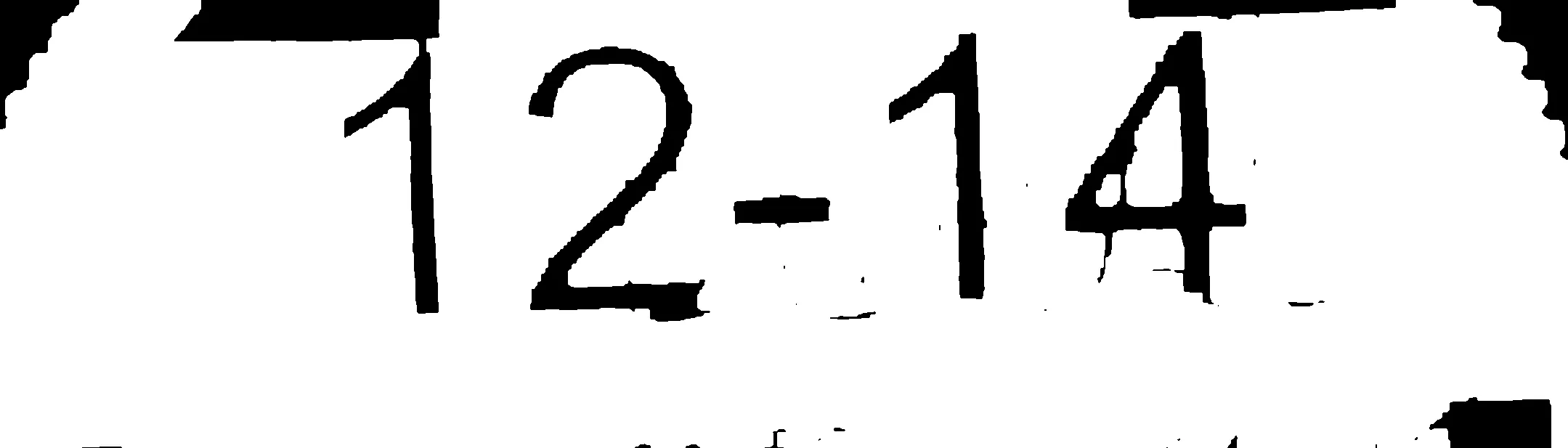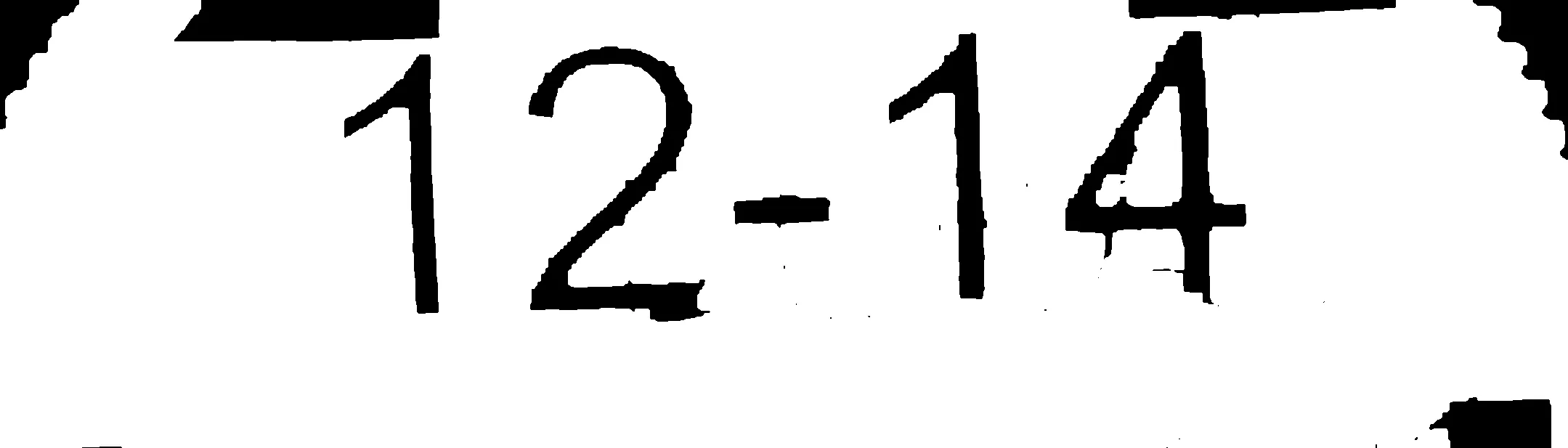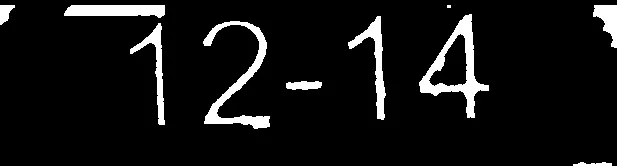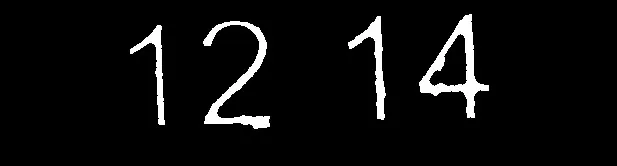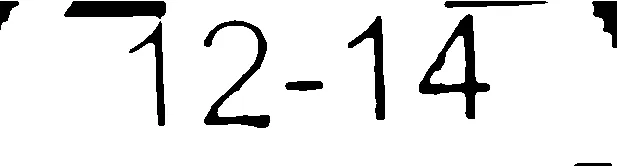我的答案基于以下假设。在您的情况下,可能没有一个符合条件。
- 您可以对分割区域中的边界框高度进行阈值限制。然后,您应该能够过滤掉其他组件。
- 您知道数字的平均笔画宽度。使用此信息最小化数字连接到其他区域的机会。您可以使用距离变换和形态学操作来实现。
这是我提取数字的步骤:
笔画宽度=8
 笔画宽度=10
笔画宽度=10

编辑
使用找到的数字轮廓的凸包准备一个掩模

使用掩码将数字区域复制到干净的图像中
笔画宽度=8

笔画宽度=10
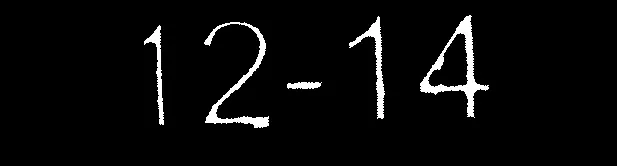
我的 Tesseract 知识有点生疏。据我所知,您可以获得字符的置信度水平。如果仍然将嘈杂区域检测为字符边界框,则可以使用此信息过滤噪声。
C++ 代码
Mat im = imread("aRh8C.png", 0);
Mat bw;
threshold(im, bw, 0, 255, CV_THRESH_BINARY_INV | CV_THRESH_OTSU);
Mat dist;
distanceTransform(bw, dist, CV_DIST_L2, CV_DIST_MASK_PRECISE);
Mat dibw;
double SWTHRESH = 8;
threshold(dist, dibw, SWTHRESH/2, 255, CV_THRESH_BINARY);
Mat kernel = getStructuringElement(MORPH_RECT, Size(3, 3));
Mat morph;
morphologyEx(dibw, morph, CV_MOP_OPEN, kernel);
dibw.convertTo(dibw, CV_8U);
Mat cont;
morph.convertTo(cont, CV_8U);
Mat binary;
cvtColor(dibw, binary, CV_GRAY2BGR);
const double HTHRESH = im.rows * .5;
vector<vector<Point>> contours;
vector<Vec4i> hierarchy;
vector<Point> digits;
findContours(cont, contours, hierarchy, CV_RETR_CCOMP, CV_CHAIN_APPROX_SIMPLE, Point(0, 0));
for(int idx = 0; idx >= 0; idx = hierarchy[idx][0])
{
Rect rect = boundingRect(contours[idx]);
if (rect.height > HTHRESH)
{
digits.insert(digits.end(), contours[idx].begin(), contours[idx].end());
rectangle(binary,
Point(rect.x, rect.y), Point(rect.x + rect.width - 1, rect.y + rect.height - 1),
Scalar(0, 0, 255), 1);
}
}
vector<Point> digitsHull;
convexHull(digits, digitsHull);
vector<vector<Point>> digitsRegion;
digitsRegion.push_back(digitsHull);
Mat digitsMask = Mat::zeros(im.rows, im.cols, CV_8U);
drawContours(digitsMask, digitsRegion, 0, Scalar(255, 255, 255), -1);
morphologyEx(digitsMask, digitsMask, CV_MOP_DILATE, kernel);
Mat cleaned = Mat::zeros(im.rows, im.cols, CV_8U);
dibw.copyTo(cleaned, digitsMask);
编辑
Java 代码
Mat im = Highgui.imread("aRh8C.png", 0);
// apply Otsu threshold
Mat bw = new Mat(im.size(), CvType.CV_8U);
Imgproc.threshold(im, bw, 0, 255, Imgproc.THRESH_BINARY_INV | Imgproc.THRESH_OTSU);
// take the distance transform
Mat dist = new Mat(im.size(), CvType.CV_32F);
Imgproc.distanceTransform(bw, dist, Imgproc.CV_DIST_L2, Imgproc.CV_DIST_MASK_PRECISE);
// threshold the distance transform
Mat dibw32f = new Mat(im.size(), CvType.CV_32F);
final double SWTHRESH = 8.0; // stroke width threshold
Imgproc.threshold(dist, dibw32f, SWTHRESH/2.0, 255, Imgproc.THRESH_BINARY);
Mat dibw8u = new Mat(im.size(), CvType.CV_8U);
dibw32f.convertTo(dibw8u, CvType.CV_8U);
Mat kernel = Imgproc.getStructuringElement(Imgproc.MORPH_RECT, new Size(3, 3));
// open to remove connections to stray elements
Mat cont = new Mat(im.size(), CvType.CV_8U);
Imgproc.morphologyEx(dibw8u, cont, Imgproc.MORPH_OPEN, kernel);
// find contours and filter based on bounding-box height
final double HTHRESH = im.rows() * 0.5; // bounding-box height threshold
List<MatOfPoint> contours = new ArrayList<MatOfPoint>();
List<Point> digits = new ArrayList<Point>(); // contours of the possible digits
Imgproc.findContours(cont, contours, new Mat(), Imgproc.RETR_CCOMP, Imgproc.CHAIN_APPROX_SIMPLE);
for (int i = 0; i < contours.size(); i++)
{
if (Imgproc.boundingRect(contours.get(i)).height > HTHRESH)
{
// this contour passed the bounding-box height threshold. add it to digits
digits.addAll(contours.get(i).toList());
}
}
// find the convexhull of the digit contours
MatOfInt digitsHullIdx = new MatOfInt();
MatOfPoint hullPoints = new MatOfPoint();
hullPoints.fromList(digits);
Imgproc.convexHull(hullPoints, digitsHullIdx);
// convert hull index to hull points
List<Point> digitsHullPointsList = new ArrayList<Point>();
List<Point> points = hullPoints.toList();
for (Integer i: digitsHullIdx.toList())
{
digitsHullPointsList.add(points.get(i));
}
MatOfPoint digitsHullPoints = new MatOfPoint();
digitsHullPoints.fromList(digitsHullPointsList);
// create the mask for digits
List<MatOfPoint> digitRegions = new ArrayList<MatOfPoint>();
digitRegions.add(digitsHullPoints);
Mat digitsMask = Mat.zeros(im.size(), CvType.CV_8U);
Imgproc.drawContours(digitsMask, digitRegions, 0, new Scalar(255, 255, 255), -1);
// dilate the mask to capture any info we lost in earlier opening
Imgproc.morphologyEx(digitsMask, digitsMask, Imgproc.MORPH_DILATE, kernel);
// cleaned image ready for OCR
Mat cleaned = Mat.zeros(im.size(), CvType.CV_8U);
dibw8u.copyTo(cleaned, digitsMask);
// feed cleaned to Tesseract