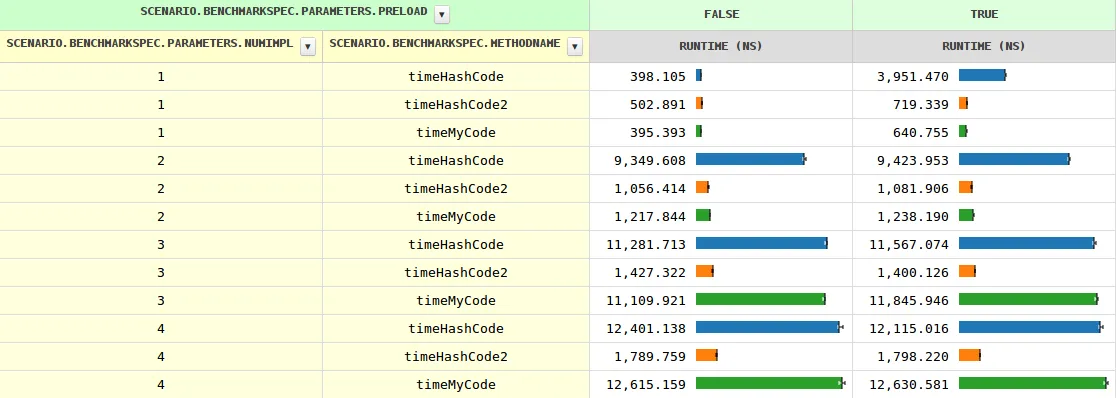
通常情况下,Java会根据给定调用方上遇到的实现数量来优化虚拟调用。这可以在我基准测试的结果中轻松地看出,当您查看返回存储的int的微不足道的方法myCode时。有一个微不足道的
static abstract class Base {
abstract int myCode();
}
具有一些类似的相同实现,例如
static class A extends Base {
@Override int myCode() {
return n;
}
@Override public int hashCode() {
return n;
}
private final int n = nextInt();
}
随着实现数量的增加,方法调用的时间从两个实现的0.4纳秒逐渐增长到11.6纳秒,然后缓慢增长。当JVM看到多个实现时,即使用preload=true,时间略有不同(因为需要进行instanceof测试)。
到目前为止都很清楚,但是hashCode的行为则相当不同。特别是,在三种情况下,它的速度要慢8-10倍。有任何想法吗?
更新
我很好奇是否可以通过手动分派来帮助可怜的hashCode,结果大幅改善了。
几个分支完美地完成了工作:
if (o instanceof A) {
result += ((A) o).hashCode();
} else if (o instanceof B) {
result += ((B) o).hashCode();
} else if (o instanceof C) {
result += ((C) o).hashCode();
} else if (o instanceof D) {
result += ((D) o).hashCode();
} else { // Actually impossible, but let's play it safe.
result += o.hashCode();
}
A.myCode()和B.myCode()之间切换。当表真正发挥作用时,就会出现10倍的减速。 - maaartinushashCode方法受JIT的特殊处理。您可以尝试使用-XX:DisableIntrinsic=_hashCode,或查看http://hg.openjdk.java.net/jdk8/jdk8/hotspot/file/a57a165b8296/src/share/vm/opto/library_call.cpp#l3924(和#l3977,#l4000,#l4103 ...搜索“hashCode”)。我无法指出* THE原因*,但猜测它隐藏在那里.... - Marco13