我想编写一个应用程序,以查找图像中的数字并将它们相加。
如何识别图像中的手写数字?
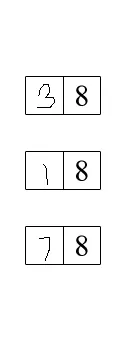
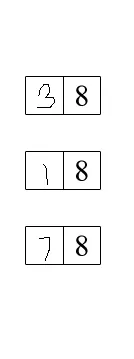
图像中有许多框,我需要获取左侧的数字并将它们加起来得出总和。我该如何实现这个功能?
编辑:我在图像上使用了Java Tesseract OCR,但没有获得任何正确的结果。我该如何进行训练?
另外,我进行了边缘检测,得到了以下结果:
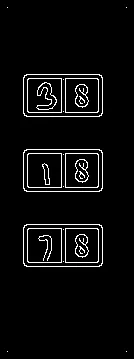
我想编写一个应用程序,以查找图像中的数字并将它们相加。
如何识别图像中的手写数字?
图像中有许多框,我需要获取左侧的数字并将它们加起来得出总和。我该如何实现这个功能?
编辑:我在图像上使用了Java Tesseract OCR,但没有获得任何正确的结果。我该如何进行训练?
另外,我进行了边缘检测,得到了以下结果:
您很可能需要执行以下操作:
对整个页面应用Hough变换算法,这应该会产生一系列页面部分。
对于每个得到的部分,再次应用相同的过程。如果当前部分产生了2个元素,则应该处理类似上述的矩形。
完成后,可以使用OCR提取数字值。
在这种情况下,我建议您查看JavaCV(OpenCV Java Wrapper),它应该允许您解决Hough Transform问题。然后,您需要类似于Tess4j(Tesseract Java Wrapper)的东西,它应该允许您提取您想要的数字。
额外注意事项,为了减少误报,您可能需要执行以下操作:
如果您确定某些坐标永远不包含您需要的数据,请裁剪图像。这应该给您一个更小的图片来处理。
如果您正在使用彩色图像,请将其转换为灰度。颜色可能会对OCR解析图像的能力产生负面影响。
编辑:根据您的评论,假设有这样的情况:
+------------------------------+
| +---+---+ |
| | | | |
| +---+---+ |
| +---+---+ |
| | | | |
| +---+---+ |
| +---+---+ |
| | | | |
| +---+---+ |
| +---+---+ |
| | | | |
| +---+---+ |
+------------------------------+
您需要裁剪图像以删除没有相关数据的区域(左侧部分)。通过裁剪图像,您将得到类似以下内容:
+-------------+
|+---+---+ |
|| | | |
|+---+---+ |
|+---+---+ |
|| | | |
|+---+---+ |
|+---+---+ |
|| | | |
|+---+---+ |
|+---+---+ |
|| | | |
|+---+---+ |
+-------------+
这个想法是运行Hough变换,以便您可以获取页面的段落,其中包含如下所示的矩形:
+---+---+
| | |
+---+---+
然后再次应用霍夫变换,得到两个线段,选择左侧的线段。
得到左侧线段后,进行OCR识别。
你可以尝试在此之前进行OCR识别,但至少OCR将会同时识别出两个数字(手写和打印),而这恰恰不是你想要的。
此外,描绘矩形的额外线条可能会使OCR失去方向,导致结果不佳。
但是,为了使用感知器,您需要一组数字输入。因此,首先需要将视觉图像转换为数字值的工具。自组织映射(SOM)使用互相连接的点阵。这些点应该被吸引到您的图像像素(见下文)。
获取二值化图像。 加载图像,转换为灰度图像,然后使用Otsu阈值方法得到一个通道为1的二值图像,像素范围为[0...255]。
执行OCR。 应用轻微的高斯模糊,然后使用Pytesseract进行OCR。
-> 二值图像 -> 水平掩模 -> 垂直掩模
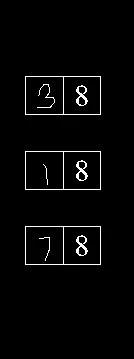


组合遮罩 -> 结果 -> 应用轻微模糊

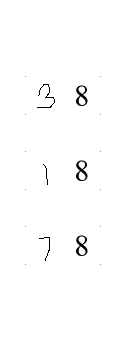

OCR的结果
38
18
78
我用Python实现了它,但你可以使用Java来适应类似的方法
import cv2
import pytesseract
pytesseract.pytesseract.tesseract_cmd = r"C:\Program Files\Tesseract-OCR\tesseract.exe"
# Load image, grayscale, Otsu's threshold
image = cv2.imread('1.png')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)[1]
# Detect horizontal lines
horizontal_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (25,1))
horizontal = cv2.morphologyEx(thresh, cv2.MORPH_OPEN, horizontal_kernel, iterations=1)
# Detect vertical lines
vertical_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (1,25))
vertical = cv2.morphologyEx(thresh, cv2.MORPH_OPEN, vertical_kernel, iterations=1)
# Remove horizontal and vertical lines
lines = cv2.bitwise_or(horizontal, vertical)
result = cv2.bitwise_not(image, image, mask=lines)
# Perform OCR with Pytesseract
result = cv2.GaussianBlur(result, (3,3), 0)
data = pytesseract.image_to_string(result, lang='eng', config='--psm 6')
print(data)
# Display
cv2.imshow('thresh', thresh)
cv2.imshow('horizontal', horizontal)
cv2.imshow('vertical', vertical)
cv2.imshow('lines', lines)
cv2.imshow('result', result)
cv2.waitKey()
tessjeract项目现在已经从网络上消失了 :( - ᴠɪɴᴄᴇɴᴛ