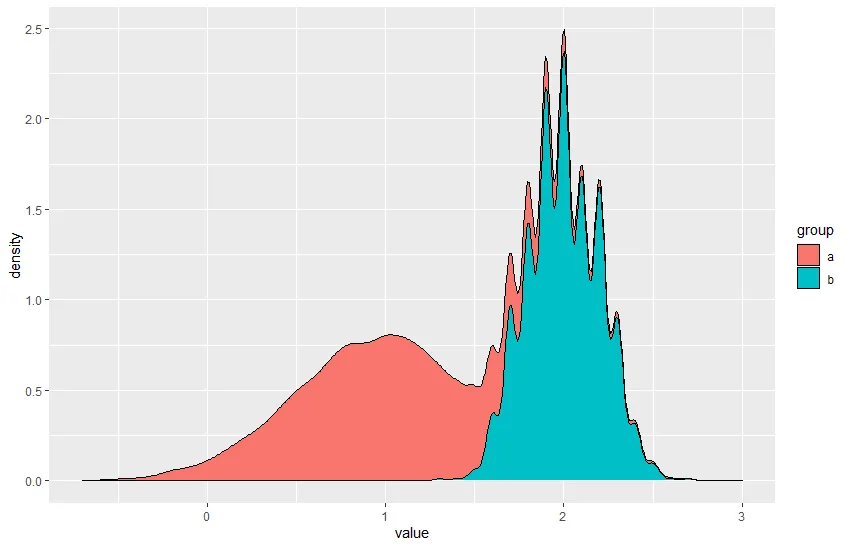
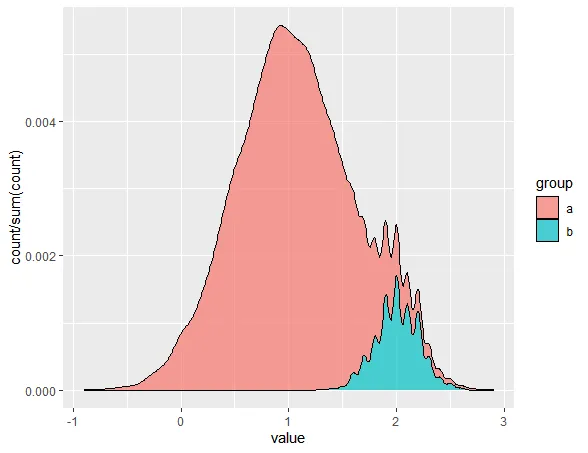
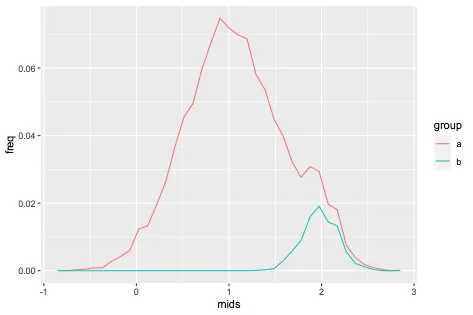
假设我们有两组不同样本大小的群体,分别为“a”和“b”。
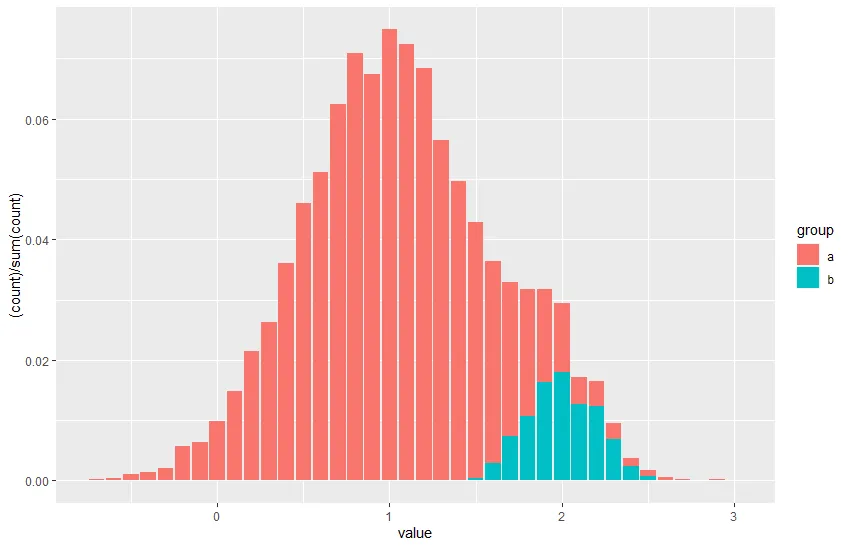
我希望将以下堆叠条形图转换为堆叠密度图。
n = 10000
set.seed(123)
dist1 = round(rnorm(n, mean = 1, sd=0.5), digits = 1)
dist2 = round(rnorm(n/10, mean = 2, sd = 0.2), digits = 1)
df = data.frame(group=c(rep("a", n), rep("b", n/10)), value=c(dist1,dist2))
我希望将以下堆叠条形图转换为堆叠密度图。
library(ggplot2)
ggplot(data=df, aes(x=value, y=(..count..)/sum(..count..), fill=group)) +
geom_bar()
我知道密度图有一个选项position="stack"。然而,结果如下所示,因为密度的高度是相对于组样本大小而不是总样本大小的。因此,小组在某种程度上被过度代表。
ggplot(data=df, aes(x=value, fill=group)) +
geom_density(position="stack")