我有一个 Pandas 的数据框,其中一个列包含具有前导零的数据。 我希望将数据框以 CSV 格式导出并保留前导零。 因此,我尝试了以下代码:
import numpy as np
import pandas as pd
import os
os.chdir(path)
x=np.array(['0134','0567','0012','0009'])
df=pd.DataFrame(x,columns=['Test'])
df.dtypes
df.Test=df.Test.astype("str")
df.to_csv("leadingZero.csv")
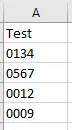
但是在 leadingZero.csv 文件中,我发现一个列中的数值前导零被删除了,而另一个列中的0则保留了下来。
你能指导我如何在 CSV 中保留前导零吗?
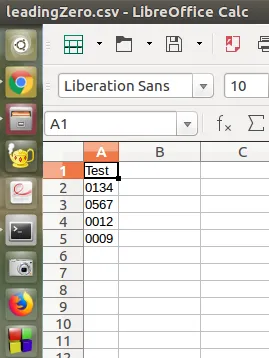
leadingZero.csv吗?还是您可能在 Excel 中打开文件..? - Chris Adams