所有这些工具都提供二进制序列化、RPC框架和IDL。我想了解它们之间的主要区别和特点(性能、易用性、编程语言支持等)。
如果您知道其他类似的技术,请在回答中提及。
如果您知道其他类似的技术,请在回答中提及。
ASN.1是ISO/ISE标准,具有易读的源语言和各种二进制和人类可读的后端。作为国际标准(而且是一个古老的标准!),它的源语言有点杂乱(就像大西洋有点潮湿一样),但是它被极好地规范化了,并且得到了相当多的支持。(如果你费劲挖掘,可能会在任何命名的语言中找到ASN.1库,如果没有,也可以使用FFI中可用的良好的C语言库。)作为标准化语言,它有着过度详细的文档并且有一些不错的教程可用。
Thrift不是一个标准。它最初来自Facebook,后来成为顶级Apache项目并开源。它的文档不太充足,尤其是教程层面,而且根据我的(虽然简短)观察,似乎没有添加其他早期努力已经做到的东西(在某些情况下还做得更好)。公平地说,它支持的语言种类相当惊人,包括一些较高知名度的非主流语言。IDL也比较类似于C语言。
Protocol Buffers不是一个标准。它是Google产品,正在向更广泛的社区发布。它在支持的语言方面有些局限(仅支持C++、Python和Java),但是对于其他语言有很多第三方支持(质量高低参差不齐)。Google几乎所有的工作都使用Protocol Buffers,因此它是经过实战测试、打磨精练的协议(虽然没有ASN.1打磨得那么精练)。它的文档比Thrift好得多,但是作为Google的产品,很可能是不稳定的(指的是一直在变,而不是不可靠)。IDL也类似于C语言。
以上所有系统都使用某种IDL定义的模式来生成目标语言的代码,然后用于编码和解码。Avro不是这样的。Avro的类型是动态的,其模式数据直接在运行时用于编码和解码(这在处理上显然有一些成本,但对于动态语言以及不需要标记类型等方面也有一些明显的优点)。它的模式使用JSON,如果已经有一个JSON库,支持在新语言中使用Avro会更容易一些。同样,像大多数重新发明轮子的协议描述系统一样,Avro也没有标准化。
个人而言,尽管我对它有爱恨情结,但我可能会在大多数RPC和消息传输目的中使用ASN.1,尽管它实际上没有RPC堆栈(您需要创建一个,但IOCs使得这变得足够简单)。
...扩展标记或模块头中的EXTENSIBILITY IMPLIED自动支持手动版本控制。据我所知,Protocol Buffers支持手动版本控制。我不知道它是否支持类似隐含可扩展性的功能(而且我懒得查)。Thrift也支持一些版本控制,但同样需要手动处理,没有隐含的可扩展性。 - JUST MY correct OPINION我们刚刚对序列化器进行了内部研究,以下是一些结果(也是我未来参考的资料!)
最大的区别在于Thrift不仅是一个序列化协议,它还是一个完整的RPC堆栈,就像现代SOAP堆栈一样。因此,在序列化之后,对象可以(但不是必须)通过TCP/IP在机器之间发送。在SOAP中,您从完全描述可用服务(远程方法)和预期参数/对象的WSDL文档开始。这些对象通过XML发送。在Thrift中,.thrift文件完全描述了可用方法、预期参数对象,并且对象通过可用序列化器之一进行序列化(使用紧凑协议,一种高效的二进制协议,在生产中最受欢迎)。
code-gen阶段为您的语言生成源代码。然后,您的应用程序源使用这些code-gen类进行IO。请注意,某些实现(例如:Microsoft的Avro库或Marc Gavel的ProtoBuf.NET)允许您直接装饰您的应用程序级POCO / POJO对象,然后该库直接使用那些装饰类而不是任何code-gen的类。我们已经看到这提供了性能提升,因为它消除了一个对象复制阶段(从应用程序级POCO / POJO字段到code-gen字段)。
这个项目(https://github.com/sidshetye/SerializersCompare)比较了C#世界中重要的序列化器。 Java人员已经有了something similar。
1000 iterations per serializer, average times listed
Sorting result by size
Name Bytes Time (ms)
------------------------------------
Avro (cheating) 133 0.0142
Avro 133 0.0568
Avro MSFT 141 0.0051
Thrift (cheating) 148 0.0069
Thrift 148 0.1470
ProtoBuf 155 0.0077
MessagePack 230 0.0296
ServiceStackJSV 258 0.0159
Json.NET BSON 286 0.0381
ServiceStackJson 290 0.0164
Json.NET 290 0.0333
XmlSerializer 571 0.1025
Binary Formatter 748 0.0344
Options: (T)est, (R)esults, s(O)rt order, (S)erializer output, (D)eserializer output (in JSON form), (E)xit
Serialized via ASN.1 DER encoding to 148 bytes in 0.0674ms (hacked experiment!)
除了性能考虑,Uber最近在他们的工程博客上评估了几个库:
https://eng.uber.com/trip-data-squeeze/
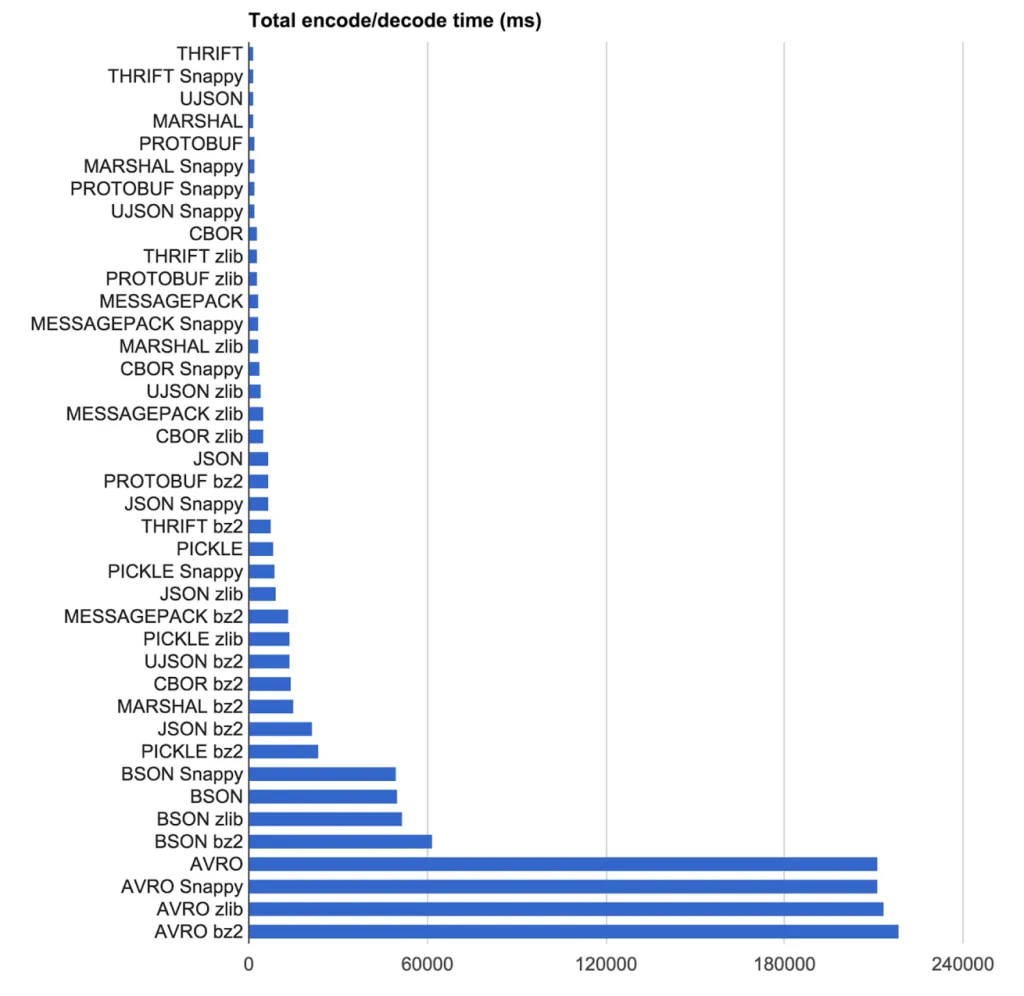
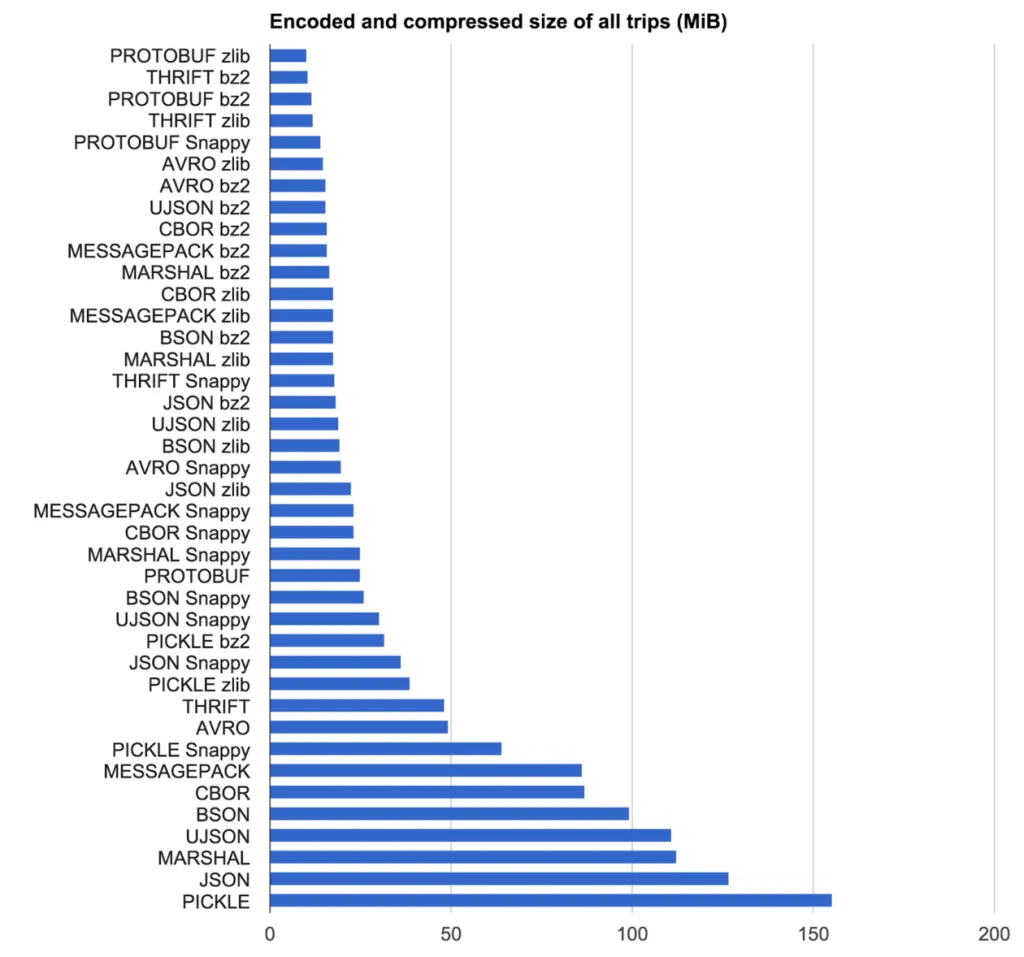
对于他们来说,胜者是使用MessagePack + zlib进行压缩。
我们的目标是找到编码协议和压缩算法的组合,以最高速度获得最紧凑的结果。我们在2,219条来自Uber纽约市的伪随机匿名行程上测试了编码协议和压缩算法的组合(将数据置于JSON文本文件中)。
这里教训是你的需求决定了哪个库适合你。对于Uber而言,由于消息传递的无模式特性,他们不能使用基于IDL的协议,这排除了很多选项。此外,对于他们来说,不仅原始编码/解码时间起作用,还有数据存储的大小。
大小结果
速度结果