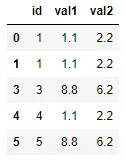
我有一个 df
id val1 val2
1 1.1 2.2
1 1.1 2.2
2 2.1 5.5
3 8.8 6.2
4 1.1 2.2
5 8.8 6.2
我想按val1和val2分组,并仅获取具有相同val1和val2组合的多个出现行的类似数据框。
最终的df:
id val1 val2
1 1.1 2.2
4 1.1 2.2
3 8.8 6.2
5 8.8 6.2
df.groupby('val1')- jezraelduplicated之前还是之后进行groupby?能否请您将此内容添加到您的答案中? - KLazdf.groupby(['val1','val2'])['id'].agg(list).reset_index(name='new')吗? - jezraeldf = df[df['val1', 'val2'].duplicated() == True].reset_index(drop=True)- Anna Christiane Kolandjian