我想合并两个数据框df1和df2,以便比较两个值info 1和info 2。将它们合并的关键在于名称列中隐藏着。Df1是“干净的”,因为它有一个名字列和一个姓氏列。然而,df2很棘手。只有一个名称列,名称可以以不同的方式给出。标准情况是名字和姓氏,但如下图所示,它可能包含由“and”或“&”分隔的两个名称,甚至可能完全不同,比如学校。
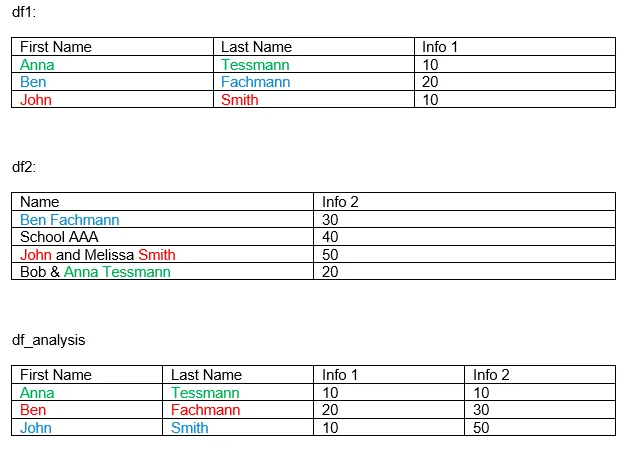
以下是代码中的虚拟数据:
data1 = [['Anna','Tessmann',10], ['Ben','Fachmann',20], ['John','Smith',10]]
df1 = pd.DataFrame(data1, columns=['FirstName','LastName','Info1'])
data2 = [['Ben Fachmann',30], ['School AAA',40], ['John and Melissa Smith',50], ['Bob & Anna Tessmann',20]]
df2= pd.DataFrame(data2, columns=['Name','Info2'])
有人知道一种有效的方法来合并这两个吗?是否有可能在类似于“df2.Name包含df1.Lastname”的情况下进行合并?或者我正在尝试解析df2.Name,我发现可以导入HumanName但我认为它无法处理“and”和“&”。
如果有什么不清楚的地方,请谅解。非常感谢您提前的任何帮助!
如果df2.name有两个名称,则值/ 2,否则值,然后将其附加到db1? - ajgrindsdf_analysis的Info2中有“Anna Tessmann”的10?另外,在data2中您有一个拼写错误,“Testmann”应该是“Tessmann”。您能否再次核对一下? - Timeless