我希望在Windows和Linux上用C或C ++实现音频编辑器。我无法在完全缩放的视图中快速显示波形。我不需要关于快速帧缓冲技术的信息。这是一个关于算法和数据结构的问题,以有效地确定要显示什么。
比如说,我想编辑一段长达2小时的5声道、48 KHz、24位声音。这是5 GB的样本数据。我希望能够从每个样本一个像素的缩放级别一直缩放到所有样本数据一次性可见。我希望应用程序感觉灵敏,即使在慢机器上,例如1 GHz Atom。当我说“灵敏”,我希望GUI更新通常在用户输入后的1/30秒内发生。
一种天真的实现方式是在决定完全缩小视图时扫描整个波形中的每个样本 - 它需要找到显示器每个像素宽度“覆盖”的所有样本的最大和最小样本值。我编写了一个简单的应用程序来测试这种方法的速度。我在我的2015年3.5 GHz Xeon上使用了一小时长的单声道、16位、44.1 KHz样本进行测试。它需要0.12秒。这太慢了数百倍。
您可以想象维护缩放数据的缓存,但我看不出如何避免在大多数插入或删除后必须重新计算整个缓存。感觉必须有更好的方法。
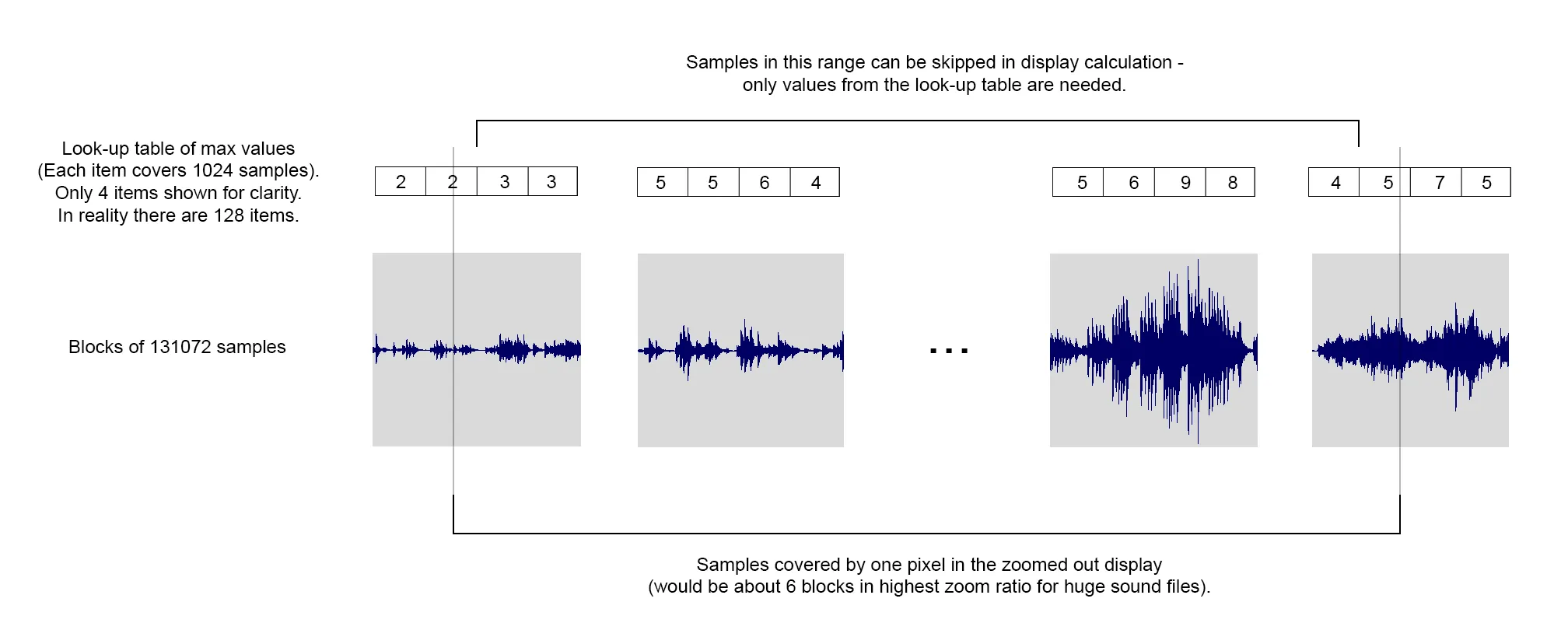
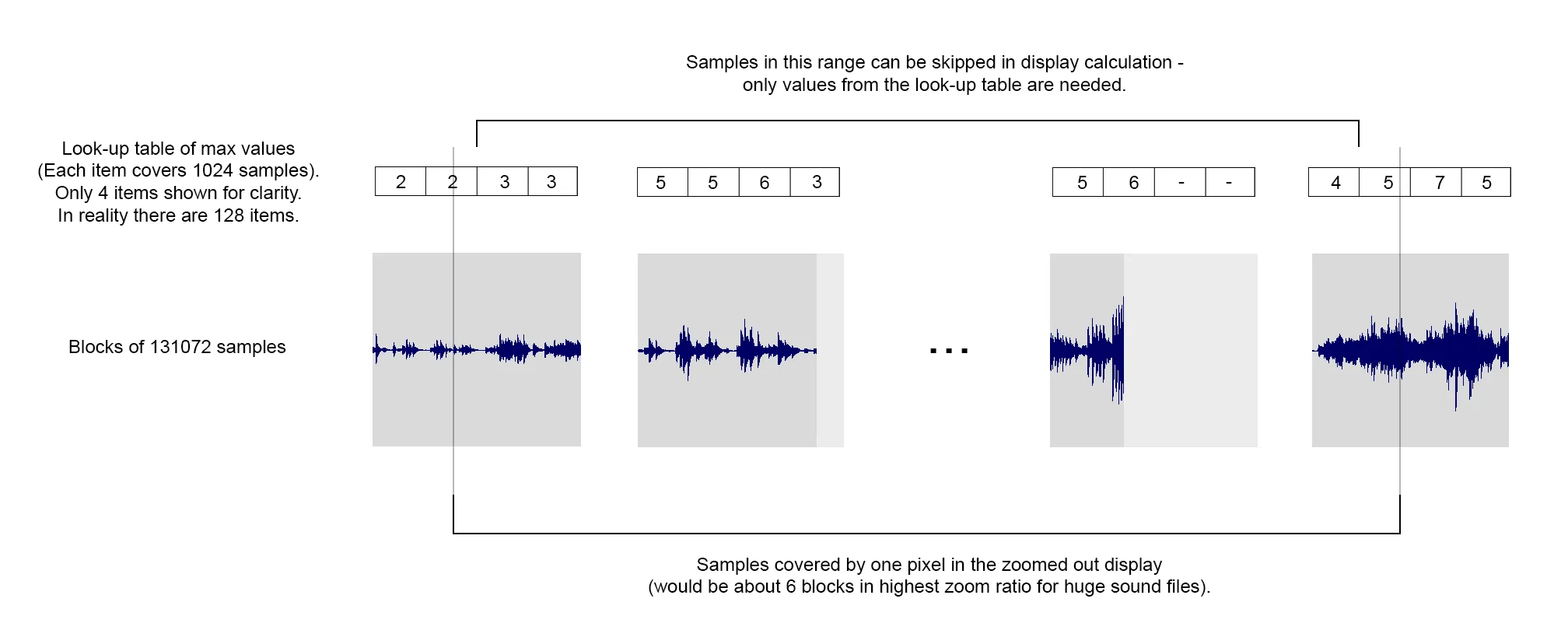
下面是一个显示我想要实现的内容的图表:
编辑:有人建议采用仅考虑缩小视图中的样本子集的方案。我得出结论,我不想这样做,因为这会损失太多有用的信息。例如,如果您正在查找声音中的故障(例如黑胶唱片转换中的单击),包括所有样本非常重要。在最坏的情况下,如果故障只有一个样本长,我仍然希望保证在完全缩小的视图中显示它。
比如说,我想编辑一段长达2小时的5声道、48 KHz、24位声音。这是5 GB的样本数据。我希望能够从每个样本一个像素的缩放级别一直缩放到所有样本数据一次性可见。我希望应用程序感觉灵敏,即使在慢机器上,例如1 GHz Atom。当我说“灵敏”,我希望GUI更新通常在用户输入后的1/30秒内发生。
一种天真的实现方式是在决定完全缩小视图时扫描整个波形中的每个样本 - 它需要找到显示器每个像素宽度“覆盖”的所有样本的最大和最小样本值。我编写了一个简单的应用程序来测试这种方法的速度。我在我的2015年3.5 GHz Xeon上使用了一小时长的单声道、16位、44.1 KHz样本进行测试。它需要0.12秒。这太慢了数百倍。
您可以想象维护缩放数据的缓存,但我看不出如何避免在大多数插入或删除后必须重新计算整个缓存。感觉必须有更好的方法。
下面是一个显示我想要实现的内容的图表:
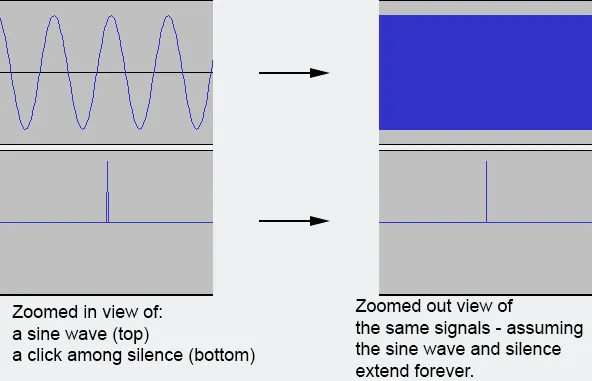
编辑:有人建议采用仅考虑缩小视图中的样本子集的方案。我得出结论,我不想这样做,因为这会损失太多有用的信息。例如,如果您正在查找声音中的故障(例如黑胶唱片转换中的单击),包括所有样本非常重要。在最坏的情况下,如果故障只有一个样本长,我仍然希望保证在完全缩小的视图中显示它。