我的页面上显示的是’,而不是'。
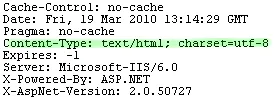
我已经在<head>标签和HTTP头中都将Content-Type设置为UTF-8:
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
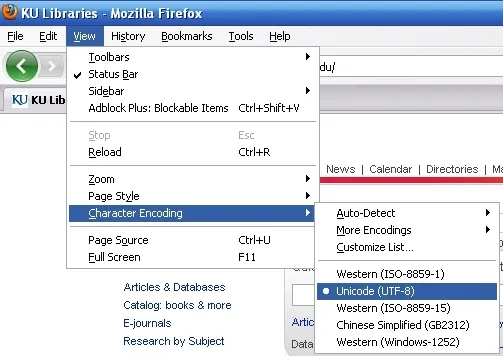
Unicode (UTF-8):
那么问题是什么,我该怎么解决呢?
我的页面上显示的是’,而不是'。
我已经在<head>标签和HTTP头中都将Content-Type设置为UTF-8:
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
Unicode (UTF-8):
那么问题是什么,我该怎么解决呢?
那么问题是什么呢,
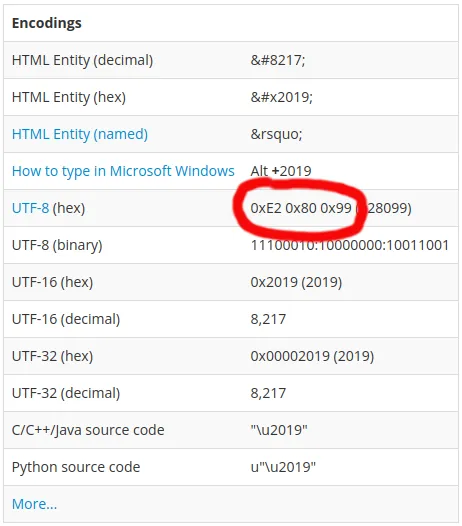
问题出在一个’(右单引号 - U+2019)字符被解码为CP-1252而不是UTF-8。如果您查看FileFormat.Info上此字符的编码表,则会发现该字符在UTF-8中由字节0xE2、0x80和0x99组成。
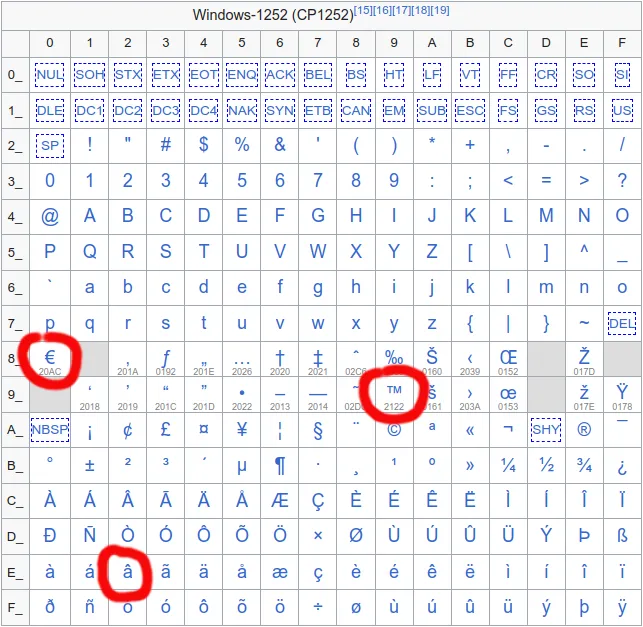
如果您查看维基百科上的CP-1252代码页布局,则会发现十六进制字节E2、80和99分别代表单个字符â、€和™。
I have the Content-Type set to UTF-8 in both my
<head>tag and my HTTP headers:<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
这只是指示客户端使用哪种编码来解释和显示字符。这并不指示您自己的程序使用哪种编码来读取、写入、存储和显示字符。确切的答案取决于服务器端平台/数据库/编程语言的使用情况。请注意,设置在HTTP响应头中的优先于HTML元标记。当页面通过http(s):// URL而不是通过file:// URL从本地磁盘文件系统打开时,才会使用HTML元标记。
Unicode (UTF-8):这只是强制客户端使用哪种编码来解释和显示字符。但实际问题是,您已经向客户端发送了编码为UTF-8的确切字符’,而不是字符’。客户端基本上使用UTF-8编码正确显示’。如果客户端被错误地指示使用例如ISO-8859-1来显示它们,那么您可能会看到ââ¬â¢。
CREATE DATABASE db_name CHARACTER SET utf8;
CREATE TABLE tbl_name (...) CHARACTER SET utf8;
以下是一些更多关于这个问题的学习链接:
确保浏览器和编辑器使用UTF-8编码而不是ISO-8859-1/Windows-1252。
或使用’。
’(Unicode代码点为U+2019 RIGHT SINGLE QUOTATION MARK)在UTF-8中的字节编码为:
0xE2 0x80 0x99。
’(Unicode代码点为U+00E2 U+20AC U+2122)在UTF-8中的字节编码为:
0xC3 0xA2 0xE2 0x82 0xAC 0xE2 0x84 0xA2。
这些是浏览器实际接收到的字节,以便在使用UTF-8处理时生成’。
这意味着您的源数据在发送到浏览器之前要经过两次字符集转换:
源码中的‘字符(U+2019)首先被编码为UTF-8字节:
0xE2 0x80 0x99
这些个别字节然后被一个Windows-125X字符集(1252、1254、1256和1258都将0xE2 0x80 0x99映射到U+00E2 U+20AC U+2122)错误解释并解码为Unicode代码点U+00E2 U+20AC U+2122,然后将这些代码点编码为UTF-8字节:
0xE2 -> U+00E2 -> 0xC3 0xA2
0x80 -> U+20AC -> 0xE2 0x82 0xAC
你需要找到第二步中进行额外转换的地方并将其删除。
0x99 -> U+2122 -> 0xE2 0x84 0xA2
我有一些文档,其中…显示为…,而ê显示为ê。这是它如何出现的(Python代码):
# Adam edits original file using windows-1252
windows = '\x85\xea'
# that is HORIZONTAL ELLIPSIS, LATIN SMALL LETTER E WITH CIRCUMFLEX
# Beth reads it correctly as windows-1252 and writes it as utf-8
utf8 = windows.decode("windows-1252").encode("utf-8")
print(utf8)
# Charlie reads it *incorrectly* as windows-1252 writes a twingled utf-8 version
twingled = utf8.decode("windows-1252").encode("utf-8")
print(twingled)
# detwingle by reading as utf-8 and writing as windows-1252 (it's really utf-8)
detwingled = twingled.decode("utf-8").encode("windows-1252")
assert utf8==detwingled
为了解决这个问题,我使用了像这样的Python代码:
with open("dirty.html","rb") as f:
dt = f.read()
ct = dt.decode("utf8").encode("windows-1252")
with open("clean.html","wb") as g:
g.write(ct)
因为有人把twingled版本插入到一个正确的UTF-8文档中,所以我只需要提取twingled部分,解twingle并重新插入。我使用了BeautifulSoup来完成这个过程。
与其说是web服务器配置错误,不如说你在内容创建时可能出现了Charlie(指字符编码错误)。你也可以通过选择windows-1252编码来强制让你的Web浏览器对页面进行twingle。但是,你的Web浏览器无法解twingle Charlie保存的文档。
注意:同样的问题也可能会发生在任何其他单字节代码页(例如Latin-1)中,而不仅仅是在windows-1252中。
当一个字符串被转换两次从Windows-1252到UTF-8时,有时会出现这种情况。
我们在一个Zend/PHP/MySQL应用程序中遇到了这个问题,这些字符似乎是因为MySQL连接没有指定正确的字符集而出现在数据库中的。我们不得不:
确保Zend和PHP在与数据库通信时使用UTF-8(默认情况下不是)
使用几个像这样的SQL查询修复损坏的字符...
UPDATE MyTable SET
MyField1 = CONVERT(CAST(CONVERT(MyField1 USING latin1) AS BINARY) USING utf8),
MyField2 = CONVERT(CAST(CONVERT(MyField2 USING latin1) AS BINARY) USING utf8);
根据需要对尽可能多的表格/列执行此操作。
如果有必要,您还可以在PHP中修复其中一些字符串。请注意,由于字符已经被编码两次,因此实际上我们需要将其从UTF-8反向转换回Windows-1252,这最初让我感到困惑。
mb_convert_encoding('’', 'Windows-1252', 'UTF-8'); // returns ’
您的字符编码不匹配;您的字符串使用一种编码(UTF-8),而解释此页面的任何内容都使用另一种编码(比如ASCII)。
请始终在http标头中指定编码,并确保与您的框架定义的编码相匹配。
示例HTTP标头:
Content-Type text/html; charset=utf-8
<configuration>
<system.web>
<globalization
fileEncoding="utf-8"
requestEncoding="utf-8"
responseEncoding="utf-8"
culture="en-US"
uiCulture="de-DE"
/>
</system.web>
</configuration>
如果在WordPress网站上出现此错误,您需要更改wp-config数据库字符集:
define('DB_CHARSET', 'utf8mb4_unicode_ci');
替代方案:
define('DB_CHARSET', 'utf8mb4');
–
或者
–