我偶然发现了一个 Stack Overflow 的问题:什么是差分执行?,其中有一个非常长并且详细的回答。虽然所有内容都很有道理... 但是当我看完后,我仍然不知道到底什么是差分执行。那它究竟是什么?
什么是差分执行?
24
- Derek Adair
2
1您可以在回答中评论并要求进一步解释... - Dr. belisarius
你还想让我试着解释一下吗?你有什么可能的解释想法? - Mike Dunlavey
2个回答
20
修改。这是我第N次尝试解释它。
假设您有一个简单的确定性过程,重复执行,始终按照相同的语句执行或过程调用顺序。 过程调用本身会按顺序将任何内容写入FIFO,并从FIFO的另一端读取相同数量的字节,如下所示:
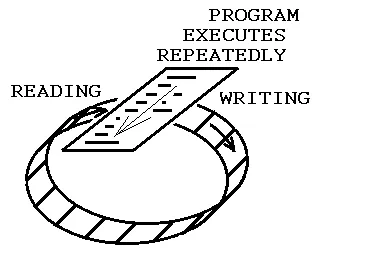
为了启动它,必须进行初始执行,其中仅发生写入操作,没有读取操作。对称地,应该有一个最终执行,其中只发生读取操作,没有写入操作。因此,有一个“全局”模式寄存器,其中包含两个位,一个启用读取,另一个启用写入,如下所示:
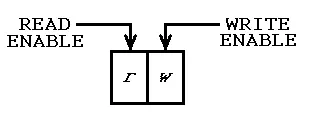
初始执行在01模式下完成,因此仅进行写入操作。 过程调用可以看到模式,因此它们知道没有先前的历史记录。 如果他们想要创建对象,可以将标识信息放入FIFO中(无需存储在变量中)。
中间执行在11模式下完成,因此读写都会发生,并且过程调用可以检测数据更改。 如果有要保持更新的对象, 它们的标识信息从FIFO中读取和写入, 因此它们可以被访问并且必要时可以修改。
最终执行在10模式下完成,因此仅发生读取操作。 在该模式下,过程调用知道它们只是在清理。 如果存在任何正在维护的对象,则从FIFO中读取其标识符,并且可以将其删除。
但是实际的程序并不总是按照相同的顺序执行。它们包含 IF 语句(以及其他改变其行为方式的方法)。那么该如何处理呢?答案是一种特殊类型的 IF 语句(以及它的终止 ENDIF 语句)。以下是它的工作原理:它会写入测试表达式的布尔值,并读取上次测试表达式的值。这样,它就可以判断测试表达式是否发生了变化,并采取行动。它所采取的行动是“临时更改模式寄存器”。
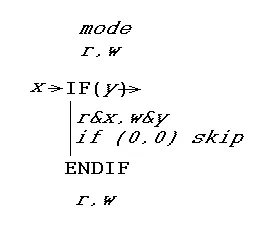
可能并不明显,但这些IF..ENDIF语句可以任意嵌套,并且可以扩展到所有其他类型的条件语句,如ELSE、SWITCH、WHILE、FOR,甚至调用基于指针的函数。同样,只要遵守模式,就可以将过程分成任意数量的子过程,包括递归。
在编程中有一条必须遵守的规则,称为“擦除模式规则”,即在 10 模式下不应进行任何重要计算,例如跟随指针或索引数组。从概念上讲,原因是模式 10 只存在于清除内容的目的。这是一个有趣的控制结构,可用于检测更改(通常是数据更改),并对这些更改采取行动。
它在图形用户界面中的使用是使一些控件或其他对象与程序状态信息保持一致。对于这种用途,三种模式分别称为SHOW(01),UPDATE(11)和ERASE(10)。 该过程最初在SHOW模式下执行,在此模式下创建控件,并填充与其相关的信息到FIFO。 然后,在UPDATE模式下进行任意数量的执行,必要时修改控件以保持与程序状态的同步。 最后,在ERASE模式下执行,其中从UI中删除控件,并清空FIFO。
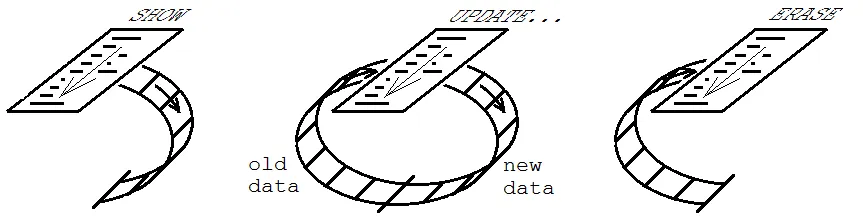
在内存管理方面,你不必编制变量名称或数据结构来保存控件。它只在当前可见控件需要时使用足够的存储空间,而潜在可见控件可以是无限的。此外,以前使用的控件的垃圾收集永远不会成为问题 - 先进先出(FIFO)充当自动垃圾收集器。
在性能方面,当它创建、删除或修改控件时,它正在花费需要花费的时间。当它仅更新控件,并且没有更改时,进行读取、写入和比较所需的周期与修改控件相比微不足道。
另一个与性能和正确性相关的考虑因素是相对于响应事件更新显示器的系统,这样的系统需要对每个事件进行响应,并且没有重复,否则显示将不正确,即使某些事件序列可能是自我取消的。在差分执行下,可以根据需要执行更新传递次数,而且在传递结束时显示始终是正确的。
这是一个极简的示例,其中有4个按钮,其中第2和第3个按钮是基于布尔变量条件的。
- 在第一次Show模式下,布尔值为false,因此只有1和4号按钮出现。
- 然后将布尔值设置为true,并在Update模式下执行第二遍,实例化了2和3号按钮并移动了4号按钮,从而得到与在第一次通行时布尔值为true相同的结果。
- 然后将布尔值设置为false,并在Update模式下执行第三遍,导致2和3号按钮被删除,4号按钮回到之前的位置。
- 最后,在Erase模式下进行第四次通行,导致所有内容消失。
(在这个示例中,更改的顺序与它们被执行的顺序相反,但这不是必要的。更改可以按任何顺序进行。)
请注意,始终包含Old和New连接在一起的FIFO恰好包含可见按钮的参数以及布尔值。
这个例子的目的是展示如何使用单个“绘制”过程,在不改变的情况下,进行任意自动增量更新和擦除。 希望清楚地表明它适用于任意深度的子程序调用和任意嵌套的条件语句,包括 switch、while 和 for 循环,调用基于指针的函数等。 如果我必须解释这一点,那么我愿意承受解释过于复杂的抨击。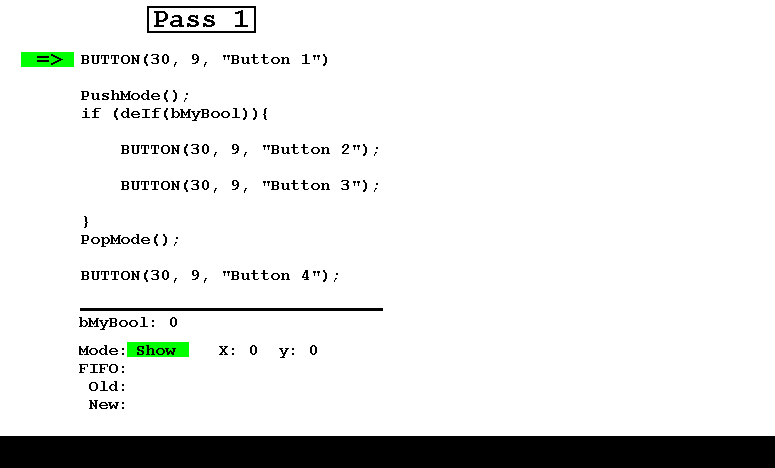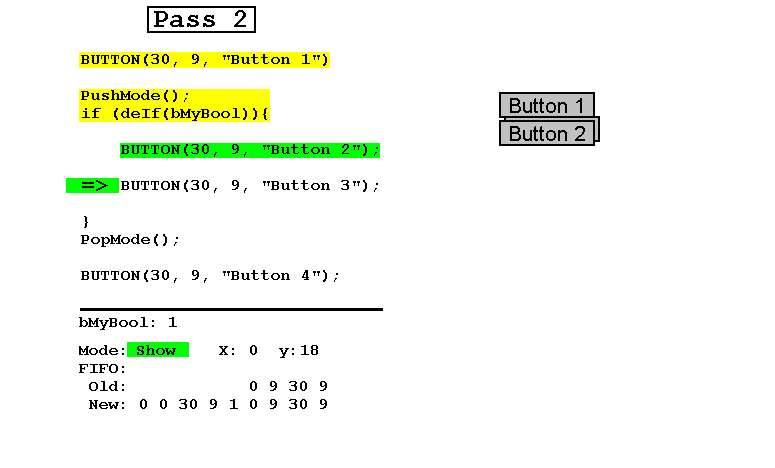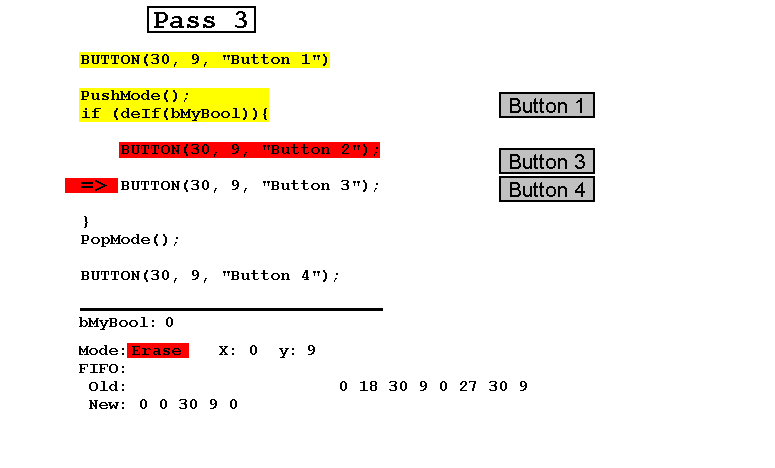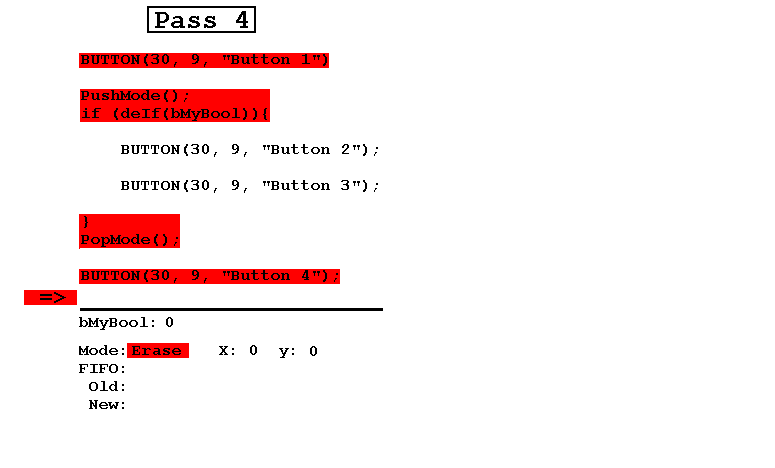
最后,在这里发布了几个简短而粗糙的视频。
** 从技术上讲,他们必须读取与上次写入的相同字节数。例如,他们可能已经写入了一个由字符计数前缀的字符串,这是可以接受的。
添加:我花了很长时间才确定这样做总是可行的,最终我证明了它。它基于一个名为同步的属性,大致意思是在程序的任何时刻,在上一遍写入的字节数等于下一遍读取的字节数。证明的想法是通过对程序长度进行归纳来完成的。最难证明的情况是程序部分由s1和IF(test)s2 ENDIF组成的情况,其中s1和s2是程序的子部分,每个部分都满足同步属性。仅用文本进行说明是枯燥无味的,但这里我尝试着用图表来解释:
它定义了Sync属性,并显示代码中每个点写入和读取的字节数,并显示它们相等。关键点是:1)在当前传递中读取的测试表达式(0或1)的值必须等于上一次传递中写入的值,2)满足Sync(s2)的条件。这满足了组合程序的Sync属性。- Mike Dunlavey
2
我认为你解释的问题在于你过于深入实现细节。01、10和11并不是真正重要的,即使FIFO对于主要思想也不相关,它只是一种方便的存储元素状态的方式。如果每个UI元素都有其状态单独存储,然后简单地发出其呈现指令,则功能将是相同的。@Gene的“解释器”解释实际上更清晰地传达了这个想法,在我看来;写入FIFO的数据基本上是将被解释的呈现指令。 - vgru
@Groo:感谢您的意见。如何呈现它总是一个谜题。真正的问题是它是一种特定于域的语言,但要使其工作需要控制结构,并且有一些顽固的读者(这是好事)会认为它是胡扯,除非我能够解释清楚。 - Mike Dunlavey
9
我阅读了所有能找到的资料并观看了视频,将尝试用一些基本原则进行描述。
概述:
这是一种基于DSL的设计模式,用于以清洁、高效的方式实现用户界面和可能的其他状态导向子系统。它专注于解决将GUI配置更改为匹配当前程序状态的问题,其中该状态包括GUI小部件本身的条件,例如用户选择选项卡、单选按钮和菜单项,小部件以任意复杂的方式出现/消失。
描述:
该模式假定:
一个需要定期更新的对象全局集合C。 一组对象类型,其中实例具有参数。 C上的一组操作:
存疑...
我不确定在现代系统中,为了修改而避免删除/添加对是否值得麻烦。发明者似乎最引以为豪的是这种优化,但更重要的想法是具有条件的简明DSL来表示表单,其中布局复杂性在DSL解释器中得到隔离。
概述:
这是一种基于DSL的设计模式,用于以清洁、高效的方式实现用户界面和可能的其他状态导向子系统。它专注于解决将GUI配置更改为匹配当前程序状态的问题,其中该状态包括GUI小部件本身的条件,例如用户选择选项卡、单选按钮和菜单项,小部件以任意复杂的方式出现/消失。
描述:
该模式假定:
一个需要定期更新的对象全局集合C。 一组对象类型,其中实例具有参数。 C上的一组操作:
- 添加A P - 将新对象A与参数P放入C中。
- 修改A P - 将C中对象A的参数更改为P。
- 删除A - 从C中删除对象A。
- 创建A H - 实例化某个对象A,使用可选提示H,并将其添加到全局状态中。(注意这里没有参数。)
- 如果B则T否则F - 根据布尔函数B(可以依赖于运行程序中的任何内容),有条件地执行命令序列T或F。
在所有的示例中,
- 全局状态是GUI屏幕或窗口。
- 对象是UI小部件。类型包括按钮、下拉框、文本框等。
- 参数控制小部件的外观和行为。
- 每次更新都包括在GUI中添加、删除和修改(例如重新定位)任意数量的小部件。
- Create命令用于创建小部件:按钮、下拉框等。
- 布尔函数依赖于底层程序状态,包括GUI控件本身的条件。因此,更改控件可能会影响屏幕。
缺失的链接
发明者从未明确说明,但一个关键思想是,每当我们预计任何组合的布尔函数值B已更改时,我们都会在表示所有可能目标集合(屏幕)的程序上运行DSL解释器。解释器通过发出Add、Delete和Modify操作序列来处理使集合(屏幕)与新的B值一致的繁琐工作。
还有一个最终的隐藏假设:DSL解释器包括某种算法,可以根据当前运行期间执行的Creates历史记录提供Add和Modify操作的参数。在GUI上下文中,这是布局算法,而Create提示是布局提示。
关键点
该技术的强大之处在于DSL解释器封装了复杂性。一个愚蠢的解释器会从删除集合(屏幕)中的所有对象(小部件)开始,然后随着通过DSL程序的步骤看到每个创建命令,为每个命令添加一个新对象(小部件)。修改永远不会发生。
差分执行只是解释器的一种更聪明的策略。它相当于保持解释器上次执行的序列化记录。这是有道理的,因为记录捕捉到目前在屏幕上的内容。在当前运行期间,解释器查询记录以决定如何使用成本最低的操作实现目标集合(小部件配置)。这意味着永远不会删除一个对象(小部件),以后再添加它,成本为2。DE总是进行修改,成本为1。如果我们在某些情况下运行解释器时B值没有更改,那么DE算法将根本不生成任何操作:记录的流已经表示目标。
当解释器执行命令时,它还在为下一次运行设置记录。
类似的算法
该算法与最小编辑距离 (MED) 有相同的味道。然而,DE比MED更简单,因为在DE序列化执行字符串中没有"重复字符",而在MED中存在。这意味着我们可以使用直接的在线贪婪算法而不是动态规划找到最优解。这就是发明者的算法所做的事情。 优点 我认为这是一种实现具有许多复杂表单的系统的良好模式,在该模式中,您希望使用自己的布局算法和/或“if else”逻辑对微件的放置进行完全控制。如果在表单逻辑中存在K个“if elses”的N层嵌套,则需要正确地获取K * 2 ^ N个不同的布局。传统的表单设计系统(至少我使用过的那些)并不支持较大的K,N值。您往往会得到大量类似的布局以及难看且难以维护的特定逻辑来选择它们。这种DSL模式似乎可以避免所有这些问题。在具有足够多的表单以抵消DSL解释器成本的系统中,即使在初始实施期间,它也将更便宜。关注点分离也是一种优势。DSL程序抽象了表单的内容,而解释器则是布局策略,根据DSL提供的提示进行操作。正确获取DSL和布局提示设计似乎是一个重要且酷炫的问题。存疑...
我不确定在现代系统中,为了修改而避免删除/添加对是否值得麻烦。发明者似乎最引以为豪的是这种优化,但更重要的想法是具有条件的简明DSL来表示表单,其中布局复杂性在DSL解释器中得到隔离。
总结
发明者目前关注于解释器如何做出决策的深入细节。这很令人困惑,因为它是针对树而不是更重要的森林。这是对森林的描述。
- Gene
9
1感谢您的关注和详细描述。实际上,我认为它的有用性来自于它是一种DSL,这是软件工程需要更多强调的部分。我只想补充两点:1)“解释器”这个词很好,但可能会误导,因为代码是编译的 - 解释器通常会有一个数量级的性能惩罚;2)它并不声称找到最小编辑距离,仅仅是合理的。 - Mike Dunlavey
3@MikeDunlavey 谢谢Mike。对于复杂的表单,提示似乎很有道理。在DSL中,不仅要说“按钮A”,还要说“在按钮B下方的列中的按钮”或类似的内容。否则您将失去良好的关注分离。提示与当前传统的布局管理器(如Java Swing)类似。在解释器中,您正在用DSL描述表单,并且一些代码块正在处理DSL以进行添加、删除和修改操作。这段代码本质上就是一个解释器。这并不新奇:自v1.0以来,Windows表单资源也有相同的功能,但它们的DSL没有条件语句! - Gene
1如果您感兴趣,这里有一个使用MFC的C++小实现在此处。 (尽管我错过了Java热潮,但我在过去几年中一直在使用VB和C#。)此外,如果您对形式证明感兴趣,可以在我的维基百科页面底部找到一个干燥无聊的正确性证明链接。 - Mike Dunlavey
1@csiz:我终于开始用JavaScript实现这个功能了,很快就会放到GitHub上。目前为止,这两个文件非常小。我对js、css、html5等方面还是新手,所以生成的网页非常简单,但它可以完成所有动态更新和事件处理。 - Mike Dunlavey
1@MikeDunlavey 我想在你把它放到Github上时看一下 :) - csiz
显示剩余4条评论
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
- 相关问题
- 7 缓存时间序列差分的聚合数据
- 3 是否可能进行差分链接?
- 87 差分执行是如何工作的?
- 30 什么是形式参数?
- 3 什么是服务?
- 20 什么是pessimization?
- 3 什么是数据类型?
- 11 什么是执行指数运算的最快算法?
- 28 什么是Backpatching?
- 10 什么是ON单元?