我有一个非常简单的数据/标签样本,我的问题是生成的决策树(pdf)重复了类名:
生成的PDF文件如下:
来自 DOCS:
列表字符串、布尔值或None,可选(默认为None) 每个目标类别的名称按升序排列。仅适用于分类,不支持多输出。如果为True,则显示类名的符号表示。
“…按升序排列”的意思对我来说不太清楚,如果我将kwarg更改为:
结果是一样的(在这种情况下很明显)。
from sklearn import tree
from sklearn.externals.six import StringIO
import pydotplus
features_names = ['weight', 'texture']
features = [[140, 1], [130, 1], [150, 0], [110, 0]]
labels = ['apple', 'apple', 'orange', 'orange']
clf = tree.DecisionTreeClassifier()
clf.fit(features, labels)
dot_data = StringIO()
tree.export_graphviz(clf, out_file=dot_data,
feature_names=features_names,
class_names=labels,
filled=True, rounded=True,
special_characters=True,
impurity=False)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_pdf("apples_oranges.pdf")
生成的PDF文件如下:
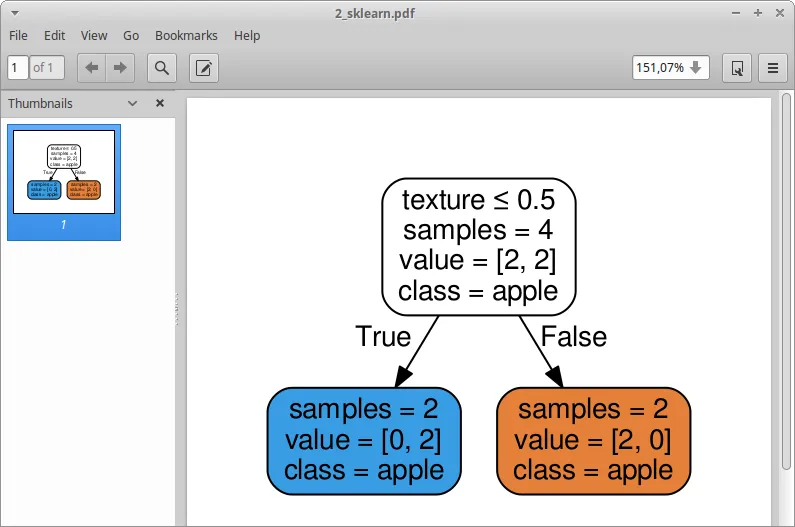
来自 DOCS:
列表字符串、布尔值或None,可选(默认为None) 每个目标类别的名称按升序排列。仅适用于分类,不支持多输出。如果为True,则显示类名的符号表示。
“…按升序排列”的意思对我来说不太清楚,如果我将kwarg更改为:
class_names=sorted(labels)
结果是一样的(在这种情况下很明显)。
['apple', 'orange']即可。 - Ken Symeclass_names=unique(labels, 'stable')。 - Dansorted(set(labels))这样,因为如果我不这样做的话,它会显示错误的位置(交换)。如果你愿意,你可以回答,我会尽快接受它。 - Hula Hula