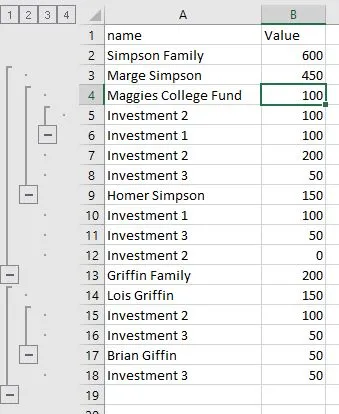
我有一个带有一些(大多数)很好分组的行的Excel文件。下面是我构建的一个示例。
是否有办法让Pandas中的read_excel生成一个保留此结构的多重索引?
是否有办法让Pandas中的read_excel生成一个保留此结构的多重索引?
from collections import defaultdict
from functools import reduce
import operator
import pandas as pd
df = pd.DataFrame({'name': ['Simpson Family', 'Marge Simpson', 'Maggies College Fund',
'MCF Investment 2', 'MS Investment 1', 'MS Investment 2', 'MS Investment 3',
'Homer Simpson', 'HS Investment 1', 'HS Investment 3', 'HS Investment 2',
'Griffin Family', 'Lois Griffin', 'LG Investment 2', 'LG Investment 3',
'Brian Giffin', 'BG Investment 3'],
'Value': [600, 450, 100, 100, 100, 200, 50, 150, 100, 50, 0, 200, 150, 100, 50, 50, 50],
'parent': ['Families', 'Simpson Family', 'Marge Simpson', 'Maggies College Fund',
'Marge Simpson', 'Marge Simpson', 'Marge Simpson', 'Simpson Family',
'Homer Simpson', 'Homer Simpson', 'Homer Simpson', 'Families',
'Griffin Family', 'Lois Griffin', 'Lois Griffin', 'Griffin Family',
'Brian Giffin']})
Value name parent
0 600 Simpson Family Families
1 450 Marge Simpson Simpson Family
2 100 Maggies College Fund Marge Simpson
3 100 MCF Investment 2 Maggies College Fund
4 100 MS Investment 1 Marge Simpson
5 200 MS Investment 2 Marge Simpson
6 50 MS Investment 3 Marge Simpson
7 150 Homer Simpson Simpson Family
8 100 HS Investment 1 Homer Simpson
9 50 HS Investment 3 Homer Simpson
10 0 HS Investment 2 Homer Simpson
11 200 Griffin Family Families
12 150 Lois Griffin Griffin Family
13 100 LG Investment 2 Lois Griffin
14 50 LG Investment 3 Lois Griffin
15 50 Brian Giffin Griffin Family
16 50 BG Investment 3 Brian Giffin
步骤1
定义一个子 -> 父亲字典和一些实用函数:
child_parent_dict = df.set_index('name')['parent'].to_dict()
tree = lambda: defaultdict(tree)
d = tree()
def get_all_parents(child):
"""Get all parents from hierarchy structure"""
while child != 'Families':
child = child_parent_dict[child]
if child != 'Families':
yield child
def getFromDict(dataDict, mapList):
"""Iterate nested dictionary"""
return reduce(operator.getitem, mapList, dataDict)
def default_to_regular_dict(d):
"""Convert nested defaultdict to regular dict of dicts."""
if isinstance(d, defaultdict):
d = {k: default_to_regular_dict(v) for k, v in d.items()}
return d
第二步
将此应用于您的数据框。使用它创建一个嵌套字典结构,这将更有效地用于重复查询。
df['structure'] = df['name'].apply(lambda x: ['Families'] + list(get_all_parents(x))[::-1])
for idx, row in df.iterrows():
getFromDict(d, row['structure'])[row['name']]['Value'] = row['Value']
res = default_to_regular_dict(d)
结果
数据帧
Value name parent \
0 600 Simpson Family Families
1 450 Marge Simpson Simpson Family
2 100 Maggies College Fund Marge Simpson
3 100 MCF Investment 2 Maggies College Fund
4 100 MS Investment 1 Marge Simpson
5 200 MS Investment 2 Marge Simpson
6 50 MS Investment 3 Marge Simpson
7 150 Homer Simpson Simpson Family
8 100 HS Investment 1 Homer Simpson
9 50 HS Investment 3 Homer Simpson
10 0 HS Investment 2 Homer Simpson
11 200 Griffin Family Families
12 150 Lois Griffin Griffin Family
13 100 LG Investment 2 Lois Griffin
14 50 LG Investment 3 Lois Griffin
15 50 Brian Giffin Griffin Family
16 50 BG Investment 3 Brian Giffin
structure
0 [Families]
1 [Families, Simpson Family]
2 [Families, Simpson Family, Marge Simpson]
3 [Families, Simpson Family, Marge Simpson, Magg...
4 [Families, Simpson Family, Marge Simpson]
5 [Families, Simpson Family, Marge Simpson]
6 [Families, Simpson Family, Marge Simpson]
7 [Families, Simpson Family]
8 [Families, Simpson Family, Homer Simpson]
9 [Families, Simpson Family, Homer Simpson]
10 [Families, Simpson Family, Homer Simpson]
11 [Families]
12 [Families, Griffin Family]
13 [Families, Griffin Family, Lois Griffin]
14 [Families, Griffin Family, Lois Griffin]
15 [Families, Griffin Family]
16 [Families, Griffin Family, Brian Giffin]
字典
{'Families': {'Griffin Family': {'Brian Giffin': {'BG Investment 3': {'Value': 50},
'Value': 50},
'Lois Griffin': {'LG Investment 2': {'Value': 100}, 'LG Investment 3': {'Value': 50},
'Value': 150},
'Value': 200},
'Simpson Family': {'Homer Simpson': {'HS Investment 1': {'Value': 100}, 'HS Investment 2': {'Value': 0}, 'HS Investment 3': {'Value': 50},
'Value': 150},
'Marge Simpson': {'MS Investment 1': {'Value': 100}, 'MS Investment 2': {'Value': 200}, 'MS Investment 3': {'Value': 50},
'Maggies College Fund': {'MCF Investment 2': {'Value': 100},
'Value': 100},
'Value': 450},
'Value': 600}}}
read_excel() 和 index_col[0,1,2,3] 来生成 pandas 数据帧。https://pandas.pydata.org/pandas-docs/stable/generated/pandas.read_excel.html
index_col : 整数,整数列表,默认为 None
用作 DataFrame 行标签的列(从 0 开始计数)。如果没有这样的列,请传入 None。如果传入列表,则这些列将合并为 MultiIndex。如果使用 usecols 选择数据子集,则 index_col 基于子集。
pandas数据框的样子。 - jppread_excel。Pandas没有任何关于你在Excel中指定的“分组”的概念。(例如通过数据 > 分组) - Brad Solomon