还有一个称为“密度数组”的对应物。这是什么意思?我进行了一些搜索,但没有找到准确的信息。
6个回答
23
假设你有一个结构体
struct SomeStruct {
int someField;
int someUselessField;
int anotherUselessField;
};
和一个数组
struct SomeStruct array[10];
那么,如果你查看这个数组中的所有someField,它们可以被视为一个单独的数组,但它们不占用连续的内存单元,因此这个数组是分步的。在这里,“stride”指的是sizeof(SomeStruct),即分步数组中两个相邻元素之间的距离。
这里提到的稀疏数组是一个更一般的概念,实际上是一个不同的概念:分步数组在跳过的内存单元中不包含零,它们只是数组的一部分。
当stride != sizeof(element)时,分步数组是通常(密集)数组的一种推广形式。
- unkulunkulu
4
1实际上,他们说步长可以是非常量,我忽略了这一点 :( - unkulunkulu
所以我又困惑了。如果稀疏和步幅之间的区别不在于“距离”是否相等,那么是什么呢? - Kos
@Kos,这有点合乎逻辑:稀疏数组只是通过列出数组中非零元素及其索引来减少内存使用(有时还能降低算法复杂度),而跨步数组则是一种表达元素在内存中位置的方式,当它们不是连续放置时。 - unkulunkulu
这是维基百科关于数组步长的定义。然而,在像C或C++这样的语言中,这不是一个有趣的属性;它只是数组元素的大小。所提到的语言是PL/1。我并不认为那个页面很有说服力——虽然我没有具体的反驳数据来证明需要编辑它。FireFly的答案也引用了这个页面。 - Jonathan Leffler
16
如果你想在一个二维数组的子集上进行操作,你需要知道这个数组的“步幅”。假设你有:
int array[4][5];
如果你想操作数组从 array[1][1] 到 array[2][3] 的元素子集,如下图所示:
+-----+-----+-----+-----+-----+
| 0,0 | 0,1 | 0,2 | 0,3 | 0,4 |
+-----+=====+=====+=====+-----+
| 1,0 [ 1,1 | 1,2 | 1,3 ] 1,4 |
+-----+=====+=====+=====+-----+
| 2,0 [ 2,1 | 2,2 | 2,3 ] 2,4 |
+-----+=====+=====+=====+-----+
| 3,0 | 3,1 | 3,2 | 3,3 | 3,4 |
+-----+-----+-----+-----+-----+
为了准确地在函数中访问数组的子集,您需要告诉被调用的函数该数组的步幅:
int summer(int *array, int rows, int cols, int stride)
{
int sum = 0;
for (int i = 0; i < rows; i++)
for (int j = 0; j < cols; j++)
sum += array[i * stride + j];
return(sum);
}
并且调用:
int sum = summer(&array[1][1], 2, 3, 5);
- Jonathan Leffler
14
“Stride”指的是“迈大步走”。
对于数组来说,这意味着仅有一些元素存在,例如每10个元素中只有一个。因此,您可以通过不存储其中的空元素来节省空间。
“Dense array”指的是许多(如果不是所有)元素都存在,因此元素之间没有空白空间。
- Bo Persson
9
7我知道的术语是“稀疏数组”(在数值计算中,我实际上听说过“稀疏矩阵”或“稀疏向量”)。 “跨步数组”是“稀疏数组”的同义词吗? - Kos
2“稀疏数组”可能是一个更常见的术语,但也许有稍微不同的含义(元素之间不是固定距离?)。术语“步幅”出现在C++标准库的
<valarray>部分中。 - Bo Persson2@Alexandre,不是的,跨步数组的步幅可以不是元素大小的倍数。而且这些概念在逻辑上是不同的。 - unkulunkulu
@unkulunkulu:当你使用一级/二级BLAS时,例如,你将数组的步长作为参数传递,并且它是一个数字。大多数情况下,步长的使用假设是一个常量步长,即要跳过的元素数量加一。 - Alexandre C.
我同意,我认为这个答案不应该被接受。在numpy/blas/lapack/eigen文档中有一些很好的(正确的)描述,可以对密集矩阵进行“跨步”操作,其中您可以在平面数组空间中沿着某个维度使用特定长度的步长。 - meawoppl
显示剩余4条评论
8
可能性1:Stride描述了一个优化数组的缓冲区数组,以便读取它。
当您使用一种方法将多维数组存储在线性存储中时,跨度描述了一个缓冲区的每个维度的大小,这将帮助您读取该数组。图像来自Nd4j(有关跨度的更多信息)。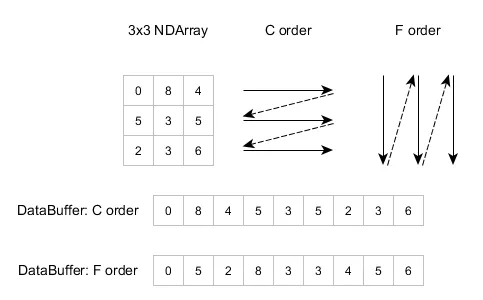 可能性2(较低级别):Stride是数组连续成员之间的距离
可能性2(较低级别):Stride是数组连续成员之间的距离
这意味着具有索引0和1的项目的地址在内存中不会连续,除非您使用单位Stride。更大的值将使项目在内存中更加分散。
这在低级别上非常有用(字长优化,重叠数组,高速缓存优化)。请参见维基百科。
当您使用一种方法将多维数组存储在线性存储中时,跨度描述了一个缓冲区的每个维度的大小,这将帮助您读取该数组。图像来自Nd4j(有关跨度的更多信息)。
可能性2(较低级别):Stride是数组连续成员之间的距离这意味着具有索引0和1的项目的地址在内存中不会连续,除非您使用单位Stride。更大的值将使项目在内存中更加分散。
这在低级别上非常有用(字长优化,重叠数组,高速缓存优化)。请参见维基百科。
- corlaez
7
我在这里添加另一个答案,因为我没有找到任何一个令人满意的现有答案。
维基百科解释了步幅的概念,并写道“步幅不能小于元素大小(这意味着元素重叠),但可以更大(表示元素之间的额外空间)。”
然而,从我找到的信息来看,跨度数组允许恰好这样做:通过允许步幅为零或负来节省内存。
跨度数组
将APL编译为JavaScript将跨度数组解释为一种表示具有数据和步幅的多维数组的方式,而不是数组的典型“矩形”表示,该表示假定隐含步幅为1。 它允许正,负和零步幅。 为什么? 它允许许多操作仅更改步幅和形状,而不更改底层数据,从而允许高效地操作大型数组。
当处理大量数据时,这种跨度表示的优点变得明显。 像转置(
⍉⍵),反转(⌽⍵)或删除操作(⍺↓⍵)这样的函数可以重用数据数组,并且只关心为其结果提供新形状,步幅和偏移量。 重新调整形状的标量,例如1000000⍴0,只能占用固定的内存量,利用了步幅可以为0的事实。
我还没有完全弄清楚这些操作将如何作为步幅和形状的操作实现,但很容易看出仅更改这些而不是底层数据将在计算方面更便宜。然而,需要记住的是,跨度表示可能会对高速缓存局部性产生负面影响,因此根据用例,使用常规矩形数组可能更好。
- FireFly
6
在高度优化的代码中,一种常见的技术是在数组中插入填充。这意味着第N个逻辑元素不再位于
图像处理是一个常见的出现此类问题的情况。图像通常具有512字节或其他“二进制圆整数”的行宽,并且许多图像操作程序使用像素的3x3邻域。结果,在某些缓存体系结构上,您可能会遇到相当多的缓存驱逐。通过在每行末尾插入“奇怪”的虚拟像素数量(例如3),您可以更改“步幅”,并且相邻行之间的缓存干扰更少。
这非常依赖于CPU,因此这里没有通用建议。
N*sizeof(T)的偏移量处。之所以这样做是一种优化,是因为某些缓存有关联限制。这意味着它们不能同时缓存某些对i,j的数组[i]和数组[j]。如果一个操作密集数组的算法使用了许多这样的对,插入一些填充可能会减少这种情况。图像处理是一个常见的出现此类问题的情况。图像通常具有512字节或其他“二进制圆整数”的行宽,并且许多图像操作程序使用像素的3x3邻域。结果,在某些缓存体系结构上,您可能会遇到相当多的缓存驱逐。通过在每行末尾插入“奇怪”的虚拟像素数量(例如3),您可以更改“步幅”,并且相邻行之间的缓存干扰更少。
这非常依赖于CPU,因此这里没有通用建议。
- MSalters
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接