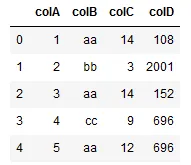
我有一个Pandas数据框,在Jupyter笔记本中工作。我想突出显示其中列对重复的行。以下是一个示例:
colA = list(range(1,6))
colB = ['aa', 'bb', 'aa', 'cc', 'aa']
colC = [14,3,14,9,12]
colD = [108, 2001, 152, 696, 696]
df = pd.DataFrame(list(zip(colA, colB, colC, colD)), columns =['colA', 'colB', 'colC', 'colD'])
display(df)
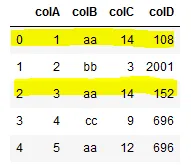
我希望突出这些行,因为colB和colC中的值是重复的:
我正在尝试使用这个lambda函数,但它抛出了一个错误(而且只针对一列):
df.style.applymap(lambda x: 'background-color : yellow' if x[colB].duplicated(keep=False) else '')
TypeError: ("'int' object is not subscriptable", 'occurred at index colA')
感谢任何帮助
