虽然这个问题已经很久了,但我决定回答它,因为它还没有被接受的答案,即使它是一个广为接受的问题。我添加了很多注释来使实现清晰明了。所以,代码应该是自解释的。但我也描述了 ImageAugmentation 的参数以进一步澄清:
在这里,original_data_dir 是父文件夹的目录,其中存在所有图像文件夹(是的,它可以从多个图像文件夹中读取)。这个参数是强制性的。
augmentation_data_dir 是您想要保存输出的文件夹目录。程序将自动创建所有子文件夹,就像它们在输入目录中出现的那样。这是完全可选的,它可以通过在输入文件夹名称后附加字符串 _augmentation 来模拟输入文件夹生成输出文件夹。
keep_original 是另一个可选参数。在许多情况下,您可能希望在输出文件夹中保留原始图像和增强的图像。如果您希望如此,请将其设置为 True(默认值)。
num_of_augmentations_per_image是每张图像要生成的增广图像的总数。虽然您只想要旋转,但此程序还设计了其他增强功能,您可以根据需要更改、添加或删除它们。我还添加了一个文档链接,在其中您将找到可以在此代码中引入的其他增强功能。默认为3,如果保留原始图像,则输出中将生成3 + 1 = 4张图像。
discard_overflow_and_underflow用于处理由于空间变换,增强点以及其下方的图像可能超出图像的分辨率的情况,您可以选择保留它们。但是,默认情况下会将其丢弃。同样,它还会丢弃width或height值为<= 0的图像。默认为True。
put_landmarks表示是否希望在输出中显示地标。根据需要将其设置为True或False。默认为False。
希望您喜欢它!
import logging
import imgaug as ia
import imgaug.augmenters as iaa
from imgaug.augmentables import Keypoint
from imgaug.augmentables import KeypointsOnImage
import os
import cv2
import re
SEED = 31
class ImageAugmentation:
def __init__(self, original_data_dir, augmentation_data_dir = None, keep_original = True, num_of_augmentations_per_image = 3, discard_overflow_and_underflow = True, put_landmarks = False):
self.original_data_dir = original_data_dir
if augmentation_data_dir != None:
self.augmentation_data_dir = augmentation_data_dir
else:
self.augmentation_data_dir = self.original_data_dir + '_augmentation'
self.keep_original = keep_original
self.num_of_augmentations_per_image = num_of_augmentations_per_image
self.discard_overflow_and_underflow = discard_overflow_and_underflow
self.put_landmarks = put_landmarks
def get_base_annotations(self):
"""This method reads all the annotation files (.txt) and make a list
of annotations to be used by other methods.
"""
base_annotations = []
def get_info(content):
"""This utility function reads the content of a single annotation
file and returns the count of total number of points and a list of coordinates
of the points inside a dictionary.
As you have provided in your question, the annotation file looks like the following:
106
282.000000 292.000000
270.000000 311.000000
259.000000 330.000000
.....
.....
Here, the first line is the number of points.
The second and the following lines gives their coordinates.
"""
lines = content.split('\n')
points = []
for line in lines[1:]:
try:
col, row = line.split(' ')
points.append((float(col), float(row)))
except:
pass
return points
for subdir, dirs, files in os.walk(self.original_data_dir):
for file in files:
ext = os.path.splitext(file)[-1].lower()
if ext not in ['.txt']:
input_image_file_dir = os.path.join(subdir, file)
image_annotation_base_dir = self.split_extension(input_image_file_dir)[0]
input_annotation_file_dir = image_annotation_base_dir + '.txt'
try:
with open(input_annotation_file_dir, 'r') as f:
content = f.read()
image_annotation_base_dir = os.path.splitext(input_annotation_file_dir)[0]
if os.path.isfile(input_image_file_dir):
image = cv2.imread(input_image_file_dir)
image_shape = image.shape
base_annotations.append({'image_file_dir': input_image_file_dir,
'annotation_data': get_info(content = content),
'image_resolution': image_shape})
except:
logging.error(f"Unable to read the file: {input_annotation_file_dir}...SKIPPED")
return base_annotations
def get_augmentation(self, base_annotation, seed):
image_file_dir = base_annotation['image_file_dir']
image_resolution = base_annotation['image_resolution']
list_of_coordinates = base_annotation['annotation_data']
ia.seed(seed)
landmarks = []
for coordinate in list_of_coordinates:
landmarks.append(Keypoint(x = coordinate[0], y = coordinate[1]))
landmarks_on_original_img = KeypointsOnImage(landmarks, shape = image_resolution)
original_image = cv2.imread(image_file_dir)
"""
Here the magic happens. If you only want rotation then remove other transformations from here.
You can even add other various types of augmentation, see documentation here:
# Documentation for image augmentation with keypoints
https://imgaug.readthedocs.io/en/latest/source/examples_keypoints.html
# Here you will find other possible transformations
https://imgaug.readthedocs.io/en/latest/source/examples_basics.html
"""
seq = iaa.Sequential([
iaa.Affine(
scale={"x": (0.8, 1.2), "y": (0.8, 1.2)},
translate_percent={"x": (-0.2, 0.2), "y": (-0.2, 0.2)},
rotate=(-90, 90),
shear=(-16, 16),
)
], random_order=True)
augmented_image, _landmarks_on_augmented_img = seq(image = original_image, keypoints = landmarks_on_original_img)
landmarks_on_augmented_img = []
for index in range(len(landmarks_on_original_img)):
landmarks_on_augmented_img.append((_landmarks_on_augmented_img[index].x,
_landmarks_on_augmented_img[index].y))
return augmented_image, landmarks_on_augmented_img
def split_extension(self, path):
return os.path.splitext(path)
def sanity_check(self, landmarks_aug, image_resolution):
for index in range(len(landmarks_aug)):
if landmarks_aug[index][0] < 0 or landmarks_aug[index][1] < 0:
return False
if landmarks_aug[index][0] >= image_resolution[1] or landmarks_aug[index][1] >= image_resolution[0]:
return False
if image_resolution[0] <= 0:
return False
if image_resolution[1] <= 0:
return False
return True
def serialize(self, serialization_data, image):
"""This method to write the annotation file and the corresponding image.
"""
image_file_dir = serialization_data['image_file_dir']
annotation_file_dir = self.split_extension(image_file_dir)[0] + '.txt'
point_coordinates = serialization_data['annotation_data']
total_points = len(point_coordinates)
head, tail = os.path.split(image_file_dir)
if not os.path.isdir(head):
os.makedirs(head)
with open(annotation_file_dir, 'w') as f:
s = ""
s += str(total_points)
s += '\n'
for point in point_coordinates:
s += "{:.6f}".format(point[0]) + ' ' + "{:6f}".format(point[1]) + '\n'
f.write(s)
if self.put_landmarks:
for index in range(total_points):
cv2.circle(image, (int(point_coordinates[index][0]), int(point_coordinates[index][1])), 2, (255, 255, 0), 2)
cv2.imwrite(image_file_dir, image)
def augmentat_with_landmarks(self):
base_annotations = self.get_base_annotations()
for base_annotation in base_annotations:
if self.keep_original == True:
base_data = {'image_file_dir': re.sub(self.original_data_dir, self.augmentation_data_dir, base_annotation['image_file_dir']),
'annotation_data': base_annotation['annotation_data']}
self.serialize(serialization_data = base_data, image = cv2.imread(base_annotation['image_file_dir']))
for index in range(self.num_of_augmentations_per_image):
image_aug, landmarks_aug = self.get_augmentation(base_annotation, seed = SEED + index)
if self.sanity_check(landmarks_aug, base_annotation['image_resolution']) or not self.discard_overflow_and_underflow:
filepath_without_ext, ext = self.split_extension(base_annotation['image_file_dir'])
filepath_for_aug_img_without_ext = re.sub(self.original_data_dir, self.augmentation_data_dir, filepath_without_ext)
new_filepath_wo_ext = filepath_for_aug_img_without_ext + '_' + str(index)
augmentation_data = {
'image_file_dir': new_filepath_wo_ext + ext,
'annotation_data': landmarks_aug
}
self.serialize(serialization_data = augmentation_data, image = image_aug)
img_aug = ImageAugmentation(original_data_dir = 'parent/folder/directory/of/img/folder', put_landmarks = True)
img_aug.augmentat_with_landmarks()
以下是代码示例的快照:
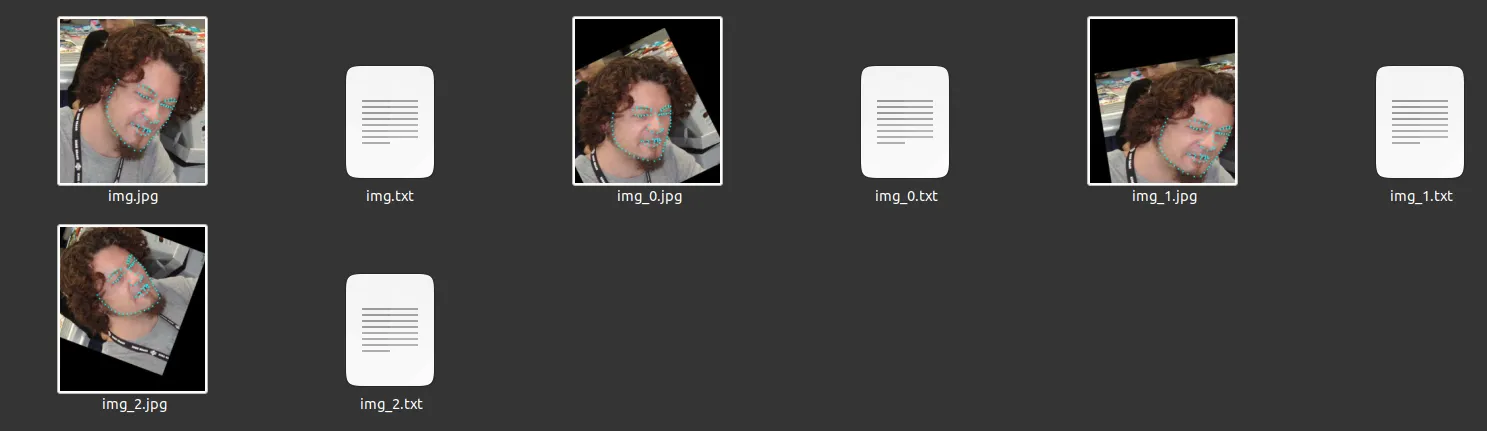
请注意,我使用了一个名为
imgaug的包。建议您安装
0.4.0版本,因为我发现它可以正常工作。请参见
此处及其被接受的答案。


