count 调用函数 find 来查看一个字母在词中从给定下标开始出现的次数(请参见下面的“代码”)。
让人困惑的部分:
使用函数“count”,我得到了以下程序输出:
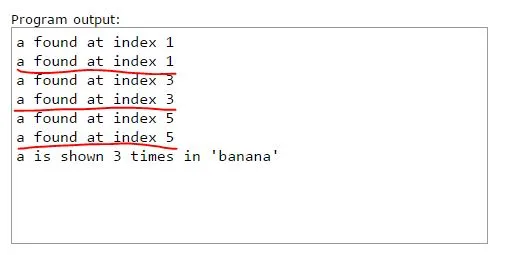
可以看到,有些输出是重复的(用红色标记)。如何避免这种情况,而不需要删除find中的print语句?这是否可能,或者我必须删除它(print语句)? 我知道这两个函数可以合并成更简单的函数,但我想了解如何通过另一个函数调用一个函数。
我还必须提到,变量count的值是正确的。唯一的问题是重复输出。
代码:
def find(word, letter, index):
start_ind = index
while index < (len(word)):
if word[index] == letter:
print "%s found at index %s" % (letter, index)
return index
index += 1
else:
print "%s is not found in string '%s' when starting from index %s" % (letter, word, start_ind)
return -1
def count(word, letter, index):
count = 0
while index < len(word):
if find(word, letter, index) != -1:
count += 1
index = find(word, letter, index) + 1
print "%s is shown %s times in '%s'" % (letter, count, word)
count("banana", "a", 0)