我实际上也遇到过类似的问题,相信我,花了我两个半小时才弄清楚。让我们通过一个例子来理解。
fig = make_subplots(rows=1,cols=2,subplot_titles=('First plot','Second plot'),
specs=[[{'type': 'scene'}, {'type': 'scene'}]])
fig.add_trace(go.Scatter3d(x=[0,1,2,3],y=[0,1,2,3],z=[0,1,2,3]), row=1,col=1)
fig.add_trace(go.Scatter3d(x=[0,1,2,3],y=[0,1,2,3], z=[0,1,2,3]), row=1,col=2)
fig.update_layout(title='Add Custom Data')
fig.show()
这将创建两个简单的scatter3d图,其中hoverdata是x、y和z轴。现在您想要将数据m=[9,8,7,6,5]添加到第一个图中。你可以在text参数中解析m并添加hovertemplate。
fig.add_trace(go.Scatter3d(x=[0,1,2,3],y=[0,1,2,3],z=[0,1,2,3],
text=[9,8,7,6], hovertemplate='<br>x:%{x}<br>y:%{y}<br>z:%{z}<br>m:%{text}'), row=1,col=1)
这应该可以正常工作。但现在我们想在第一张图(或任何图)上添加一个名为n=[5,6,7,8]的列表。这次我们将使用customdata参数。
fig.add_trace(go.Scatter3d(x=[0,1,2,3],y=[0,1,2,3],z=[0,1,2,3],
text=[9,8,7,6],customdata=[5,6,7,8],
hovertemplate='<br>x:%{x}<br>y:%{y}<br>z:%{z}<br>m:%{text}<br>n:%{customdata}'), row=1,col=1)
现在假设我们要添加第三个自定义数据列表。这就是棘手的部分。您不能解析两个自定义数据列表中的列表,然后调用customdata [0]和customdata [1],这并不简单。我们的第三个列表是k=[2,4,6,8]。
我们需要像这样的customdata=[[[5],[2]],[[6],[4]],[[7],[6]],[[8],[8]]], 这样它应该可以正常工作。基本上,我们需要给 plotly 一个单独的列表(或数组),其中每个元素都是您想要显示的所有点的列表。
fig.add_trace(go.Scatter3d(x=[0,1,2,3],y=[0,1,2,3],z=[0,1,2,3],
text=[9,8,7,6],customdata=[[[5],[2]],
[[6],[4]],
[[7],[6]],
[[8],[8]]],
hovertemplate='<br>x:%{x}<br>y:%{y}<br>z:%{z}<br>m:%{text}<br>n:%{customdata[0]}<br>k:%{customdata[1]}'), row=1,col=1)
我们已经快要完成了,但还有一件事情未完成。手动创建像我们在customdata中给出的列表是非常繁琐的工作,因此我们将使用强大的库import numpy as np来自动化它。
n = [5,6,7,8]
k = [2,4,6,8]
nk = np.empty(shape=(4,2,1), dtype='object')
nk[:,0] = np.array(n).reshape(-1,1)
nk[:,1] = np.array(k).reshape(-1,1)
fig.add_trace(go.Scatter3d(x=[0,1,2,3],y=[0,1,2,3],z=[0,1,2,3],
text=[9,8,7,6],customdata=nk,
hovertemplate='<br>x:%{x}<br>y:%{y}<br>z:%{z}<br>m:%{text}<br>n:%{customdata[0]}<br>k:%{customdata[1]}'), row=1,col=1)
BOOM!如果您想直接从数据框中添加数据,可以将df ['Column name'] 解析为np.array(n)。
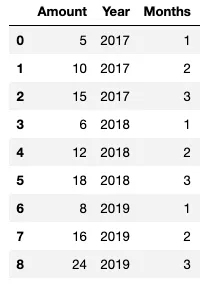
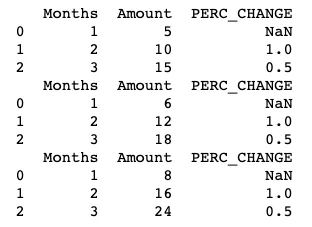
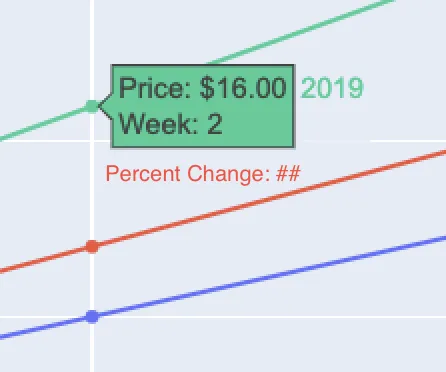
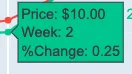
'<br>%Change:{text}'并在括号中指定text=group_dfff.PERC_CHANGE- 这正是我想要的。然而,text 变量是一个内置的东西,所以我仍然不确定如何添加第四、第五个及更多标签,我希望在悬停数据点时能够看到它们... - DGomonov