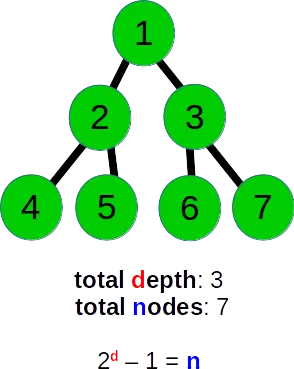
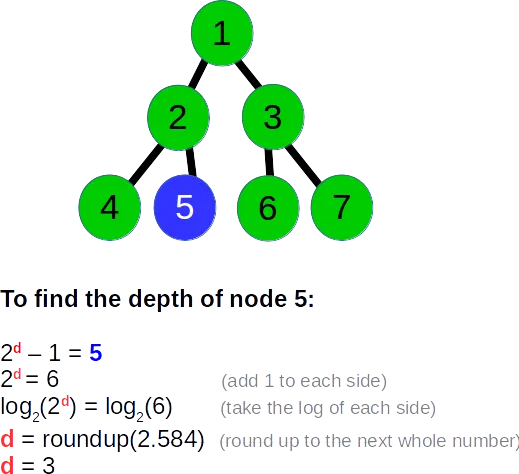
我有一棵树作为广度优先搜索的输入,我想知道算法在进行时处于哪个层级?
# Breadth First Search Implementation
graph = {
'A':['B','C','D'],
'B':['A'],
'C':['A','E','F'],
'D':['A','G','H'],
'E':['C'],
'F':['C'],
'G':['D'],
'H':['D']
}
def breadth_first_search(graph,source):
"""
This function is the Implementation of the breadth_first_search program
"""
# Mark each node as not visited
mark = {}
for item in graph.keys():
mark[item] = 0
queue, output = [],[]
# Initialize an empty queue with the source node and mark it as explored
queue.append(source)
mark[source] = 1
output.append(source)
# while queue is not empty
while queue:
# remove the first element of the queue and call it vertex
vertex = queue[0]
queue.pop(0)
# for each edge from the vertex do the following
for vrtx in graph[vertex]:
# If the vertex is unexplored
if mark[vrtx] == 0:
queue.append(vrtx) # mark it as explored
mark[vrtx] = 1 # and append it to the queue
output.append(vrtx) # fill the output vector
return output
print breadth_first_search(graph, 'A')
它以树作为输入图形,在每次迭代中,我想要的是打印出当前处理的层级。