我有一组未排序的嘈杂的X,Y点。然而,它们在世界中形成了一条路径。我想使用线段的近似数据来绘制这些数据的算法。
这类似于如何使用线拟合算法来选择线性数据的近似值。我的问题只是更难,因为路径弯曲并围绕着世界旋转。 alt text http://www.praeclarum.org/so/pathfinder.png 有人知道任何标准/稳健/易于理解的算法来完成这个任务吗?
问答:
你所说的“嘈杂”是什么意思?如果我有一个理想的路径实现,那么我的点集将从该理想路径中采样,并添加高斯噪声到X和Y元素。我不知道该噪声的平均值或标准偏差。我可能能够猜测标准偏差...
这些点是否靠近但不在某个理想但复杂的路径上,你试图对其进行近似?是的。
你是否具有关于路径形状的先验信息?获取此类信息的其他方法?不幸的是没有。
这类似于如何使用线拟合算法来选择线性数据的近似值。我的问题只是更难,因为路径弯曲并围绕着世界旋转。 alt text http://www.praeclarum.org/so/pathfinder.png 有人知道任何标准/稳健/易于理解的算法来完成这个任务吗?
问答:
你所说的“嘈杂”是什么意思?如果我有一个理想的路径实现,那么我的点集将从该理想路径中采样,并添加高斯噪声到X和Y元素。我不知道该噪声的平均值或标准偏差。我可能能够猜测标准偏差...
这些点是否靠近但不在某个理想但复杂的路径上,你试图对其进行近似?是的。
你是否具有关于路径形状的先验信息?获取此类信息的其他方法?不幸的是没有。
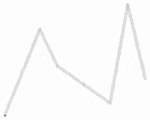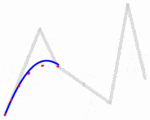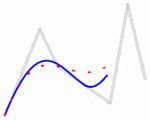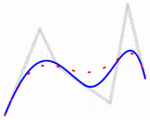 然而,这并没有解决点的排序成路径的问题;有许多方法可供考虑:
然而,这并没有解决点的排序成路径的问题;有许多方法可供考虑:
{kind=link}