我有一个表中的数据是倾斜的,然后将其与另一个较小的表进行比较。 我了解到在连接操作中使用盐值可以起到作用——即在具有倾斜数据的大表中的键后附加一个随机数,该随机数范围内的行将与没有倾斜数据的小表中相同范围的随机数重复。因此,匹配发生在偏斜表的特定盐化键的其中一个重复值中将会命中。 我还阅读到,在执行 groupby 操作时使用盐值是有帮助的。我的问题是,当在键后附加随机数时,它是否会破坏分组?如果是这样,那么 group by 操作的含义是否改变。
3个回答
15
我的问题是:如果在密钥后附加随机数,是否会破坏分组?
是的,会破坏分组。为了缓解这个问题,您可以对键进行两次分组操作。首先使用加盐键进行分组,然后去除盐并再次分组。第二次分组将采用部分聚合数据,从而显着减少偏斜影响。
例如:
import org.apache.spark.sql.functions._
df.withColumn("salt", (rand * n).cast(IntegerType))
.groupBy("salt", groupByFields)
.agg(aggFields)
.groupBy(groupByFields)
.agg(aggFields)
- Gelerion
2
1如果聚合函数是像计数、百分位和标准差这样的函数,这样做会产生正确的结果吗?我知道对于求和来说,这种方法是有效的,但不确定对于计数、百分位和标准差是否能提供正确的结果。 - Shubham Gupta
如果我们尝试在倾斜的列上使用子字符串创建新列会怎样? - Sarang
3
我的问题是,如果在键后附加随机数字,是否会破坏分组?如果是这样,则分组操作的含义已经改变。
是的,向现有密钥添加盐会破坏分组。但是,正如@Gelerion在他的答案中提到的那样,您可以按盐和原始密钥进行分组,然后按原始密钥进行分组。这对于聚合(例如计数、最小值、最大值、总和)非常有效,可以将子组的结果合并。下面的示例说明了计算偏斜数据框的最大值的示例。
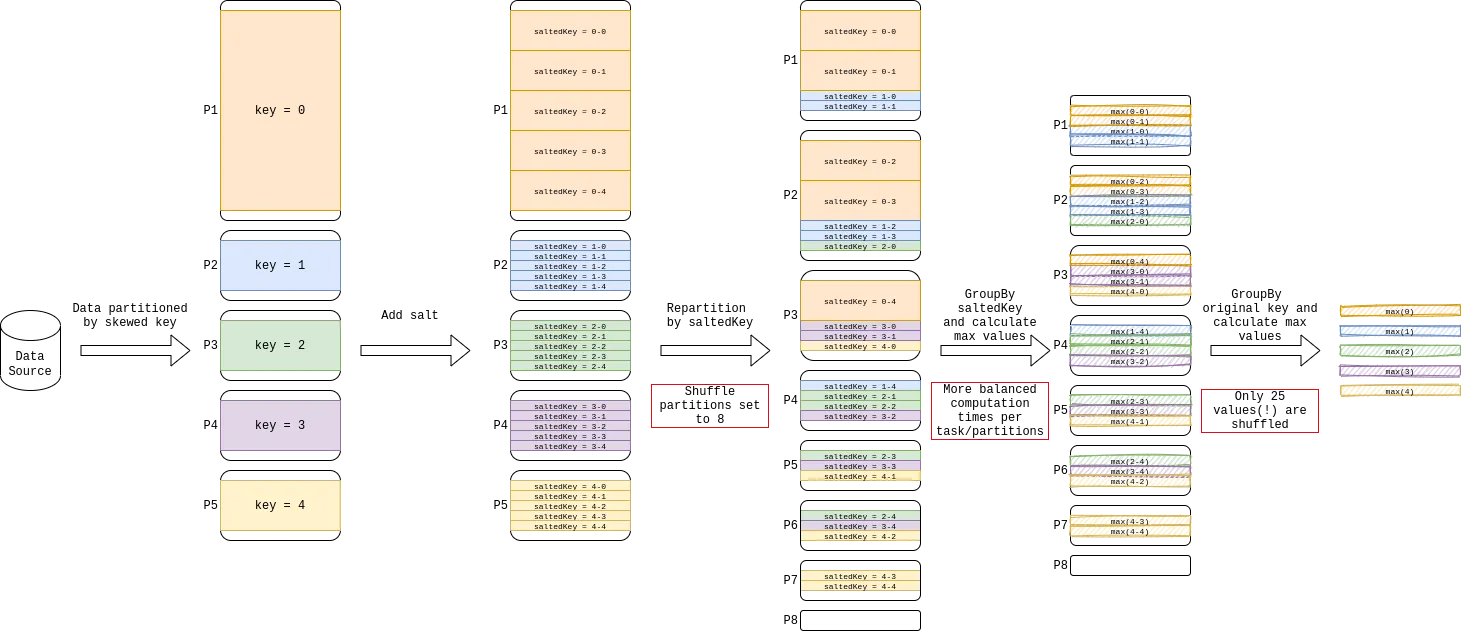
- Michael Heil
1
我真的很想看到查询计划和性能的整个比较,包括有盐和无盐计算。 - Jacek Laskowski
1
var df1 = Seq((1,"a"),(2,"b"),(1,"c"),(1,"x"),(1,"y"),(1,"g"),(1,"k"),(1,"u"),(1,"n")).toDF("ID","NAME")
df1.createOrReplaceTempView("fact")
var df2 = Seq((1,10),(2,30),(3,40)).toDF("ID","SALARY")
df2.createOrReplaceTempView("dim")
val salted_df1 = spark.sql("""select concat(ID, '_', FLOOR(RAND(123456)*19)) as salted_key, NAME from fact """)
salted_df1.createOrReplaceTempView("salted_fact")
val exploded_dim_df = spark.sql(""" select ID, SALARY, explode(array(0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19)) as salted_key from dim""")
//val exploded_dim_df = spark.sql(""" select ID, SALARY, explode(array(0 to 19)) as salted_key from dim""")
exploded_dim_df.createOrReplaceTempView("salted_dim")
val result_df = spark.sql("""select split(fact.salted_key, '_')[0] as ID, dim.SALARY
from salted_fact fact
LEFT JOIN salted_dim dim
ON fact.salted_key = concat(dim.ID, '_', dim.salted_key) """)
display(result_df)
- Shiva
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接