Google支持在robots.txt文件中使用通配符。下面的指令会阻止Googlebot爬取带有任何参数的网页:
Disallow: /*?
Disallow: /*?
这不会阻止许多其他蜘蛛爬取这些URL,因为通配符不是标准的robots.txt的一部分。
谷歌可能需要一段时间才能从搜索索引中删除您已阻止的URL。额外的URL可能仍会被索引数月。在它们被阻止后,您可以使用网络管理员工具中的“删除URL”功能来加快此过程。但那是一个手动过程,您必须粘贴每个要删除的单独URL。
如果Googlbot找不到没有参数的URL版本,则使用此robots.txt规则也可能会损害您网站的谷歌排名。如果您经常链接到带参数的版本,则可能不想在robots.txt中阻止它们。最好使用以下其中之一的选项。
更好的选择是在每个页面上使用rel canonical元标签。
因此,您的两个示例URL将在head部分中添加以下内容:
<link rel="canonical" href="http://www.site.com/shop/maxi-dress">
这可以告诉Googlebot不要索引太多页面变量,只索引您选择的URL的“规范”版本。与使用robots.txt不同的是,即使它们使用各种URL参数,Googlebot仍然能够爬行并为它们分配值。
另一个选择是登录Google网站管理员工具,并使用“抓取”部分中的“URL参数”功能。
在那里,点击“添加参数”。您可以将“product_type”设置为“不影响页面内容”,以便Google不会爬行和索引具有该参数的页面。
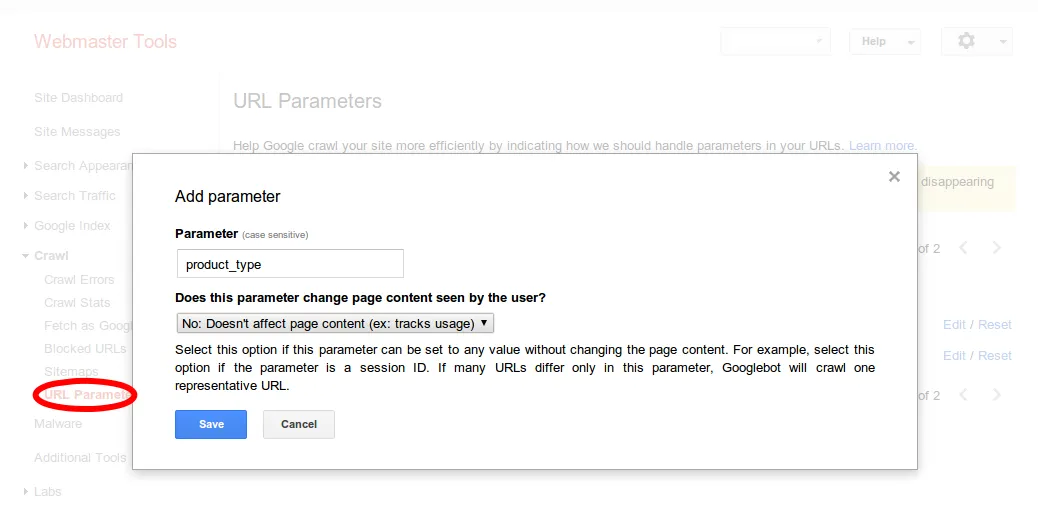
对于每个不更改页面的参数都做同样的操作。