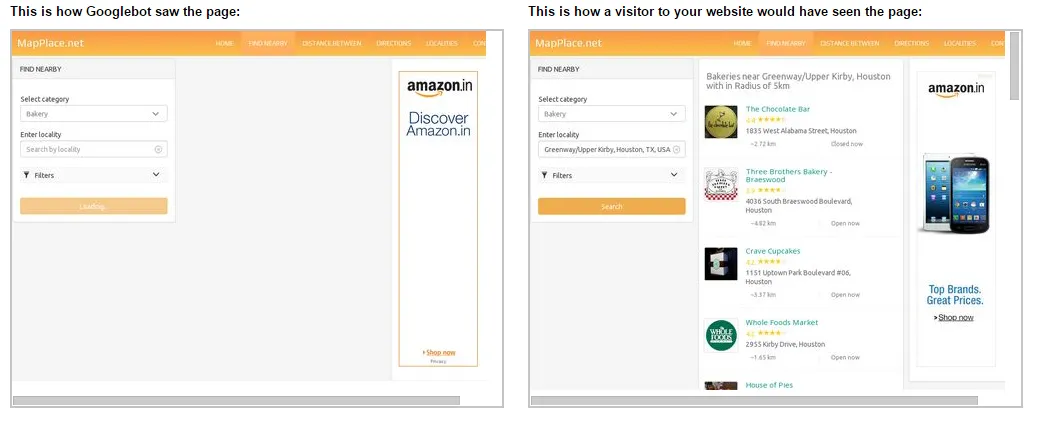
我在我的网站应用中使用了Google地图、地点、方向JavaScript API。根据用户输入,应用程序通过对Google API进行ajax调用来加载不同的地点。幸运的是,Google最近能够抓取ajax。
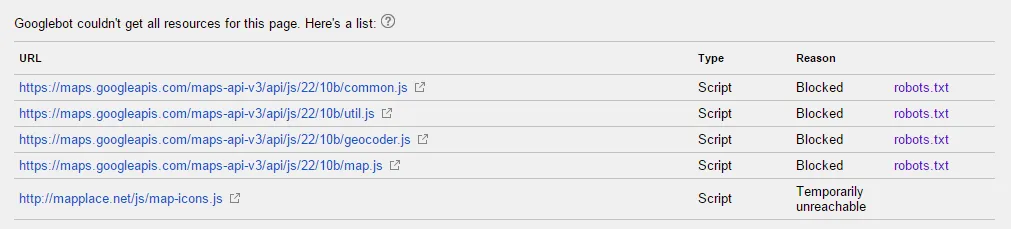
当我在Google网站管理员工具的“获取Google”功能中检查URL时,响应如下:
当我在Google网站管理员工具的“获取Google”功能中检查URL时,响应如下:
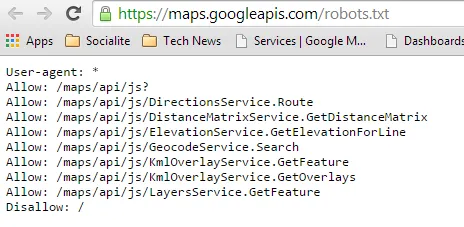
这里是谷歌地图API的robots.txt文件
if (navigator.userAgent !== 'Googlebot') { // 加载地图和其他内容 } else { // 显示一个图片代替地图或者什么都不做。 }另外,可以参考用户代理 https://support.google.com/webmasters/answer/1061943?hl=en - Aishwat Singh