我将尝试合并/连接两列文本,这两列都包含相关但分开的文本数据,用 "|" 分隔,另外还需要将某些名称替换为 "" 并将 | 替换为 '\n'。
例如,原始数据可能是:
如果我想合并/连接以得到完整的姓名,并删除与“Smith”相关的条目,则最终的数据框应该如下所示:
例如,原始数据可能是:
First Names Last Names
0 Jim|James|Tim Simth|Jacobs|Turner
1 Mickey|Mini Mouse|Mouse
2 Mike|Billy|Natasha Mills|McGill|Tsaka
如果我想合并/连接以得到完整的姓名,并删除与“Smith”相关的条目,则最终的数据框应该如下所示:
First Names Last Names Full Names
0 Jim|James|Tim Simth|Jacobs|Turner James Jacobs\nTim Turner
1 Mickey|Mini Mouse|Mouse Mickey Mouse\nMini Mouse
2 Mike|Billy|Natasha Mills|McGill|Tsaka Mike Mills\nBilly McGill\nNatasha Tsaka
目前我的做法是:
def parse_merge(df, col1, col2, splitter, new_col, list_to_exclude):
orig_order = pd.Series(list(df.index)).rename('index')
col1_df = pd.concat([orig_order, df[col1], df[col1].str.split(splitter, expand=True)], axis = 1)
col2_df = pd.concat([orig_order, df[col2], df[col2].str.split(splitter, expand=True)], axis = 1)
col1_melt = pd.melt(col1_df, id_vars=['index', col1], var_name='count')
col2_melt = pd.melt(col2_df, id_vars=['index', col2], var_name='count')
col2_melt['value'] = '(' + col2_melt['value'].astype(str) + ')'
col2_melt = col2_melt.rename(columns={'value':'value2'})
melted_merge = pd.concat([col1_melt, col2_melt['value2']], axis = 1 )
if len(list_to_exclude) > 0:
list_map = map(re.escape, list_to_exclude)
melted_merge.ix[melted_merge['value2'].str.contains('|'.join(list_map)), ['value', 'value2']] = ''
melted_merge[new_col] = melted_merge['value'] + " " + melted_merge['value2']
如果我调用:
parse_merge(names, 'First Names', 'Last Names', 'Full Names', ['Smith'])
数据变成:
Index First Names count value value2 Full Names
0 0 Jim|James|Tim 0 Jim Smith ''
1 1 Mickey|Mini 0 Mickey Mouse Mickey Mouse
2 2 Mike|Billy|Natasha 0 Mike Mills Mike Mills
我不确定如何在没有循环的情况下完成这个任务,或者是否有更有效/完全不同的方法。
感谢所有的建议!

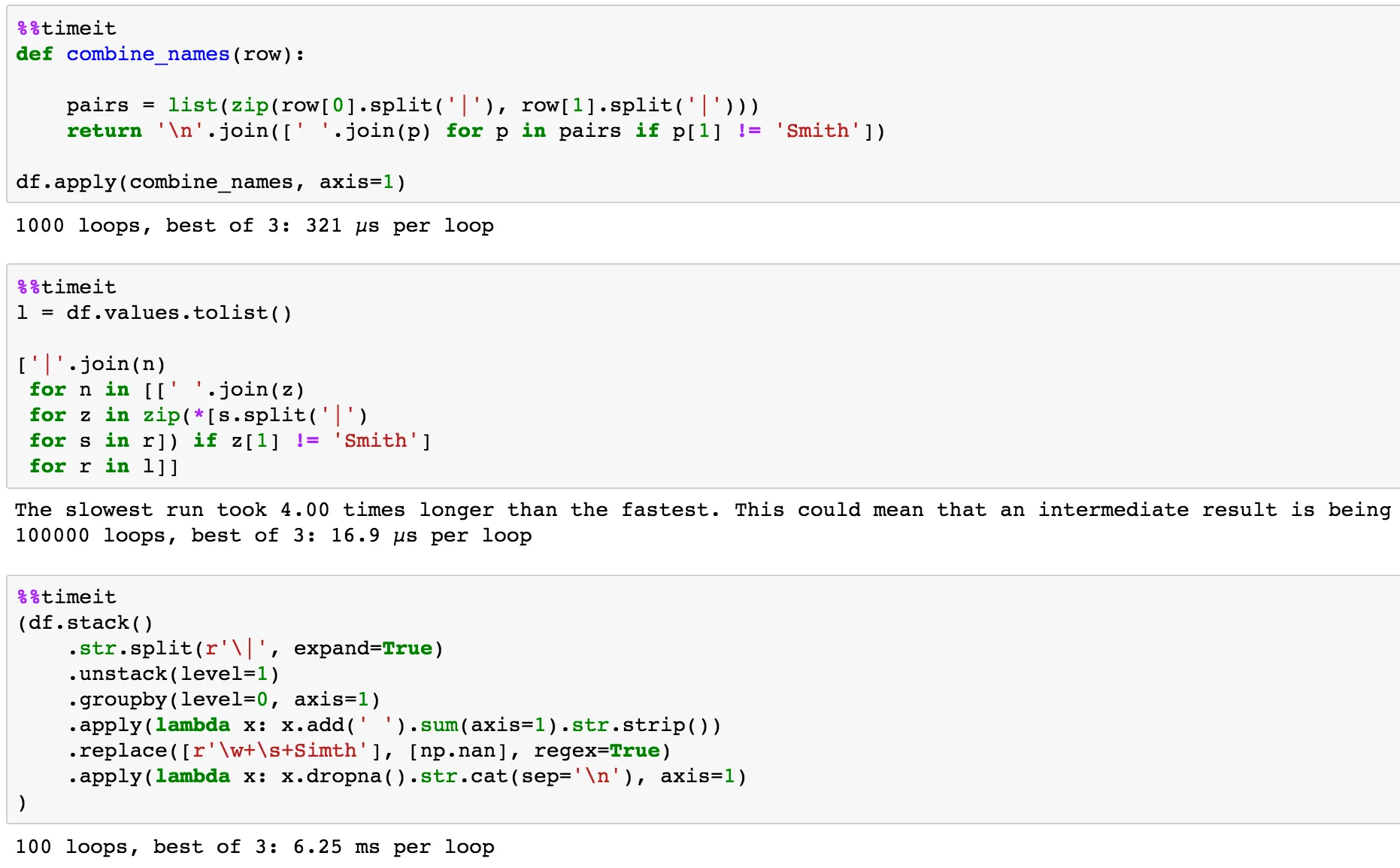
combine_names函数中,但它只能接受一个参数。传递的参数是行(假设轴设置为1)。如果您有超过这两列,则还可以像这样调用它:df[['First Names', 'Last Names']].apply(combine_names, axis=1)。回到您的第一个观点,您可以将if p[1] != 'Simth'更改为类似于if p[1] not in ['Simth', 'John', 'King']的内容。 - Alex