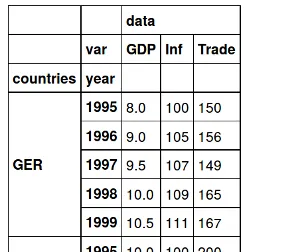
您可以使用OrderedDict来对数据进行分组:
import csv
from collections import OrderedDict,defaultdict
from itertools import islice
with open("out.csv") as f:
od = OrderedDict()
r = csv.reader(f, delimiter=" ")
header = next(r)
years = header[2:]
zipped = zip(*r)
countries = OrderedDict.fromkeys(zipped[0]).keys()
it = iter(countries)
for row in zip(*zipped[1:]):
if row[0] == "GDP":
key = next(it)
od.setdefault(key, defaultdict(list))
od[key]["Years"] = years
od[key]["Country"] = [key] * len(years)
od[key][row[0]].extend(islice(row,1,None))
输出:
OrderedDict([('USA', defaultdict(<type 'list'>, {'GDP': ['10', '11', '12', '12', '13'], 'Inf': ['100', '120', '130', '120', '110'], 'Years': ['1995', '1996', '1997', '1998', '1999'], 'Trade': ['200', '220', '210', '235', '250']})), ('GER', defaultdict(<type 'list'>, {'GDP': ['8', '9', '9.5', '10', '10.5'], 'Inf': ['100', '105', '107', '109', '111'], 'Years': ['1995', '1996', '1997', '1998', '1999'], 'Trade': ['150', '156', '149', '165', '167']}))])
毫无疑问,对Pandas更有经验的人能够找到更好的方法来做这件事情,但是下面这种方式至少可以创建一个dataframe:
df = pd.DataFrame(columns=["Country","Years","GDP","Inf","Trade"])
for k,v in od.items():
df_temp = pd.DataFrame((v[k] for k in ["Country","Years","GDP","Inf","Trade"] ),["Country","Years","GDP","Inf","Trade"]).transpose()
f = df.append(df_temp,ignore_index=True)
print(df)
输出:
Country Years GDP Inf Trade
0 USA 1995 10 100 200
1 USA 1996 11 120 220
2 USA 1997 12 130 210
3 USA 1998 12 120 235
4 USA 1999 13 110 250
5 GER 1995 8 100 150
6 GER 1996 9 105 156
7 GER 1997 9.5 107 149
8 GER 1998 10 109 165
9 GER 1999 10.5 111 167
如果您的文件比较大,您可以按需创建dataframe,并每次重置OrderedDict以避免将所有数据存储在字典中。此外,您只需要在主代码之外附加最后一个组即可。如果使用python2还可以使用itertools.islice获取所有切片并使用itertools.izip进行压缩。
import csv
from collections import OrderedDict,defaultdict
from itertools import islice,izip
df = pd.DataFrame(columns=["Country","Years","GDP","Inf","Trade"])
with open("out.csv") as f:
od = OrderedDict()
r = csv.reader(f, delimiter=" ")
header = next(r)
years = header[2:]
zipped = izip(*r)
countries = OrderedDict.fromkeys(next(zipped)).keys()
it = iter(countries)
for row in izip(*zipped):
if row[0] == "GDP":
if od:
for k, v in od.items():
df_temp = pd.DataFrame((v[k] for k in ["Country","Years","GDP","Inf","Trade"] ), ["Country","Years","GDP","Inf","Trade"]).transpose()
df = df.append(df_temp, ignore_index=True)
od = OrderedDict()
key = next(it)
od.setdefault(key, defaultdict(list))
od[key]["Years"] = years
od[key]["Country"] = [key] * len(years)
od[key][row[0]].extend(islice(row, 1, None))
for k,v in od.items():
df_temp = pd.DataFrame((v[k] for k in ["Country","Years","GDP","Inf","Trade"] ), ["Country","Years","GDP","Inf","Trade"]).transpose()
df = df.append(df_temp, ignore_index=True)
print(df)
这将再次产生相同的输出:
Country Years GDP Inf Trade
0 USA 1995 10 100 200
1 USA 1996 11 120 220
2 USA 1997 12 130 210
3 USA 1998 12 120 235
4 USA 1999 13 110 250
5 GER 1995 8 100 150
6 GER 1996 9 105 156
7 GER 1997 9.5 107 149
8 GER 1998 10 109 165
9 GER 1999 10.5 111 167