对于一个非常简单的分类问题,其中我有一个目标向量[0,0,0,....0]和一个预测向量[0,0.1,0.2,....1],交叉熵损失更快/更好地收敛还是均方误差损失?
当我绘制它们时,似乎MSE损失具有较低的误差边界。为什么会这样?
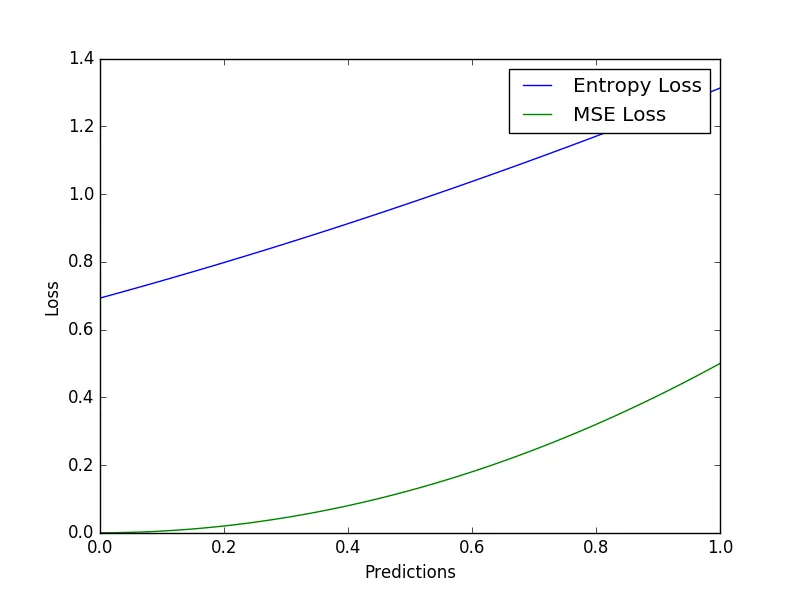 或者例如当我将目标设置为[1,1,1,1....1]时,我得到以下结果:
或者例如当我将目标设置为[1,1,1,1....1]时,我得到以下结果:
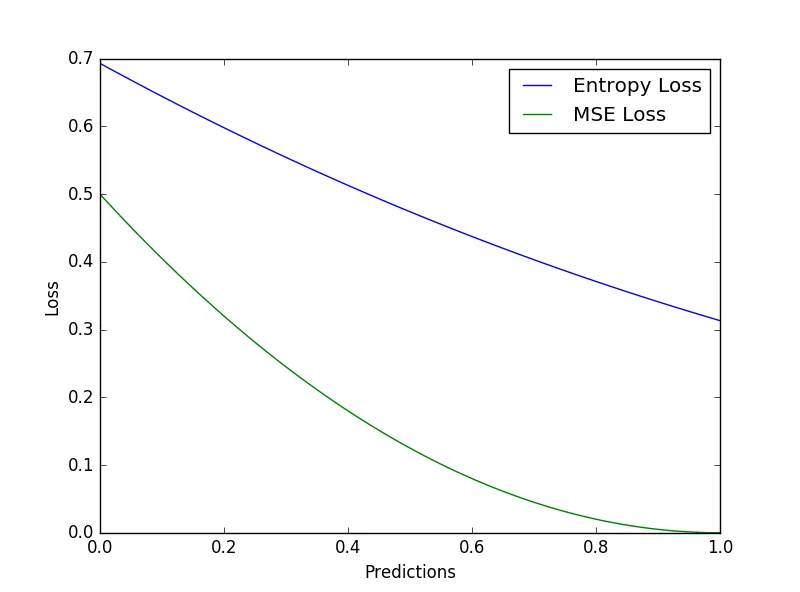
或者例如当我将目标设置为[1,1,1,1....1]时,我得到以下结果:
或者例如当我将目标设置为[1,1,1,1....1]时,我得到以下结果:
高斯分布(正态分布)的均值为,方差为
,表示为
在机器学习中,我们经常处理均值为0,方差为1的分布(或将数据转换为具有均值为0和方差为1)。此时正态分布为
,称为标准正态分布。
对于具有权重参数和精度(逆方差)参数
的正态分布模型,给定输入
,观察到单个目标
t的概率由以下方程表示:
,其中
是分布的均值,由模型计算得出:
现在,给定输入,目标向量
的概率可以表示为:
取左右两边的自然对数可得:
其中 是正态函数的对数似然,通常训练模型涉及相对于参数
最大化似然函数。现在参数
的最大似然函数为 (关于常数项的
可以省略)。
训练模型时省略常数不会影响收敛。
mean可得均方误差。在深入了解更一般的交叉熵函数之前,我将解释特定类型的交叉熵 - 二元交叉熵。
二元交叉熵的假设是目标变量的概率分布来自伯努利分布。根据维基百科
伯努利分布是一个离散型随机变量的概率分布,它取值1的概率为 p,取值0的概率为 q=1-p
伯努利分布随机变量的概率为
, 其中
,p 是成功的概率。
这可以简单地写成
两边取负自然对数得到
这被称为二元交叉熵。涉及内容与编程有关。
交叉熵的泛化遵循随机变量是多元的(来自多项式分布)的一般情况,其概率分布如下:
,
你听起来有点困惑...
[0,0.1,0.2,....1]这样的(即具有非整数分量)时,正如你所说,问题是一个回归问题(而不是分类问题);在分类设置中,我们通常使用独热编码的目标向量,其中只有一个分量为1,其余都为0[1,1,1,1....1]的目标向量可以是回归设置中的情况,也可以是多标签多类别分类的情况,即输出可能同时属于多个类别除此之外,你选择的图表,水平轴上的百分比(?),令人困惑 - 我从未在ML诊断中看到过这样的图表,也不太确定它们到底代表什么或者为什么它们有用...
如果你想详细讨论分类设置中的交叉熵损失和准确性,可以看看我在这个答案中的内容。
针对你的第一个问题,简单回答如下:
对于一个非常简单的分类问题...使用交叉熵损失函数和均方误差损失函数哪个会更好/更快地收敛?
答案是,当与sigmoid激活结合使用时,MSE损失函数会导致多个局部最小值的非凸代价函数。这是由Andrew Ng教授在他的讲座中解释的:
Lecture 6.4 — Logistic Regression | Cost Function — [ Machine Learning | Andrew Ng]
我想同样适用于softmax激活的多类别分类。
我倾向于不同意之前给出的答案。关键在于交叉熵和均方误差损失是相同的。
现代神经网络使用参数空间的最大似然估计(MLE)来学习其参数。最大似然估计器由参数空间上概率分布的乘积的argmax给出。如果我们应用对数变换并通过自由参数的数量缩放MLE,我们将获得由训练数据定义的经验分布的期望。
此外,我们可以假设不同的先验条件,例如高斯或Bernoulli,它们分别产生MSE损失或Sigmoid函数的负对数似然。
更多阅读资料: Ian Goodfellow的《深度学习》