我的初步想法是使用如下所示的列表推导式,但是正如评论中指出的那样,这比使用groupby和transform方法要慢。我将保留此答案以展示不要这样做:
In [94]: df = pd.DataFrame({'Color': 'Red Red Blue'.split(), 'Value': [100, 150, 50]})
In [95]: df['Counts'] = [sum(df['Color'] == df['Color'][i]) for i in xrange(len(df))]
In [96]: df
Out[100]:
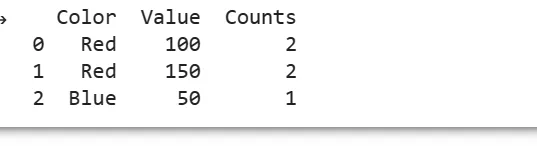
Color Value Counts
0 Red 100 2
1 Red 150 2
2 Blue 50 1
[3 rows x 3 columns]
@unutbu的方法在具有多个列的数据框中变得复杂,这使得编码更加简单。如果您正在使用小型数据框,则此方法更快(请参见下文),但否则,您不应该使用此方法。
In [97]: %timeit df = pd.DataFrame({'Color': 'Red Red Blue'.split(), 'Value': [100, 150, 50]}); df['Counts'] = df.groupby(['Color']).transform('count')
100 loops, best of 3: 2.87 ms per loop
In [98]: %timeit df = pd.DataFrame({'Color': 'Red Red Blue'.split(), 'Value': [100, 150, 50]}); df['Counts'] = [sum(df['Color'] == df['Color'][i]) for i in xrange(len(df))]
1000 loops, best of 3: 1.03 ms per loop