我希望找到更改多级数据框中特定列名称的方法。
使用以下数据:
data = {
('A', '1', 'I'): [1, 2, 3, 4, 5],
('B', '2', 'II'): [1, 2, 3, 4, 5],
('C', '3', 'I'): [1, 2, 3, 4, 5],
('D', '4', 'II'): [1, 2, 3, 4, 5],
('E', '5', 'III'): [1, 2, 3, 4, 5],
}
dataDF = pd.DataFrame(data)
这段代码无法运行:
dataDF.rename(columns = {('A', '1', 'I'):('Z', '100', 'Z')}, inplace=True)
结果:
A B C D E
1 2 3 4 5
I II I II III
0 1 1 1 1 1
1 2 2 2 2 2
2 3 3 3 3 3
3 4 4 4 4 4
4 5 5 5 5 5
也不是这样:
dataDF.columns.values[0] = ('Z', '100', 'Z')
结果:
A B C D E
1 2 3 4 5
I II I II III
0 1 1 1 1 1
1 2 2 2 2 2
2 3 3 3 3 3
3 4 4 4 4 4
4 5 5 5 5 5
但是以上代码的组合起来可以正常工作!!!
dataDF.columns.values[0] = ('Z', '100', 'Z')
dataDF.rename(columns = {('A', '1', 'I'):('Z', '100', 'Z')}, inplace=True)
dataDF
结果:
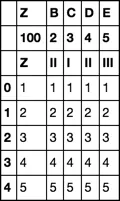
Z B C D E
100 2 3 4 5
Z II I II III
0 1 1 1 1 1
1 2 2 2 2 2
2 3 3 3 3 3
3 4 4 4 4 4
4 5 5 5 5 5
这是Pandas的一个bug吗?
dataDF.columns.values[0] = ('Z', '100', 'Z')对我来说是可行的。在此之后打印dataDF.columns反映出更改是正确的。这里有什么我忽略的东西吗?Pandas 在更新版本中解决了这个问题吗? - Jon