我想创建一个索引列表,其循环范围为0到m - 1,长度为n。到目前为止,我已经这样做:
import numpy as np
m = 7
n = 12
indices = [np.mod(i, m) for i in np.arange(n)]
这将导致以下结果:
[0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4]
有没有更快的方法实现这个?感谢任何建议。
只需使用列表推导式将往返于Python的过程去掉即可。从numpy获得良好的速度取决于确保您的循环保持在numpy内部,而不是在Python本身中进行循环。
np.mod(np.arange(n), m)
np.tile函数。np.tile(np.arange(m),(n+m-1)//m)[:n]
示例运行 -
In [58]: m,n = 7,12
In [59]: np.tile(np.arange(m),(n+m-1)//m)[:n]
Out[59]: array([0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4])
如果您想要高效地处理中等到大规模的数据,NumPy是一个不错的选择。在本节中,我们将测试 NumPy 在 m 和 n 变化的情况下的解决方案速度。
设置:
import numpy as np
def resize(m,n):
return np.resize(np.arange(m), n)
def mod(m,n):
return np.mod(np.arange(n), m)
def tile(m,n):
return np.tile(np.arange(m),(n+m-1)//m)[:n]
# Setup inputs and timeit those on posted NumPy approaches
m_ar = [10,100,1000]
s_ar = [10,20,50,100,200,500,1000] # scaling array
resize_timings = []
mod_timings = []
tile_timings = []
sizes_str = []
for m in m_ar:
for s in s_ar:
n = m*s+m//2
size_str = str(m) + 'x' + str(n)
sizes_str.append(size_str)
p = %timeit -o -q resize(m,n)
resize_timings.append(p.best)
p = %timeit -o -q mod(m,n)
mod_timings.append(p.best)
p = %timeit -o -q tile(m,n)
tile_timings.append(p.best)
# Use pandas to study results
import pandas as pd
df_data = {'Resize':resize_timings,'Mod':mod_timings,'Tile':tile_timings}
df = pd.DataFrame(df_data,index=sizes_str)
FGSZ = (20,6)
T = 'Timings(s)'
FTSZ = 16
df.plot(figsize=FGSZ,title=T,fontsize=FTSZ).get_figure().savefig("timings.png")
比较所有三个
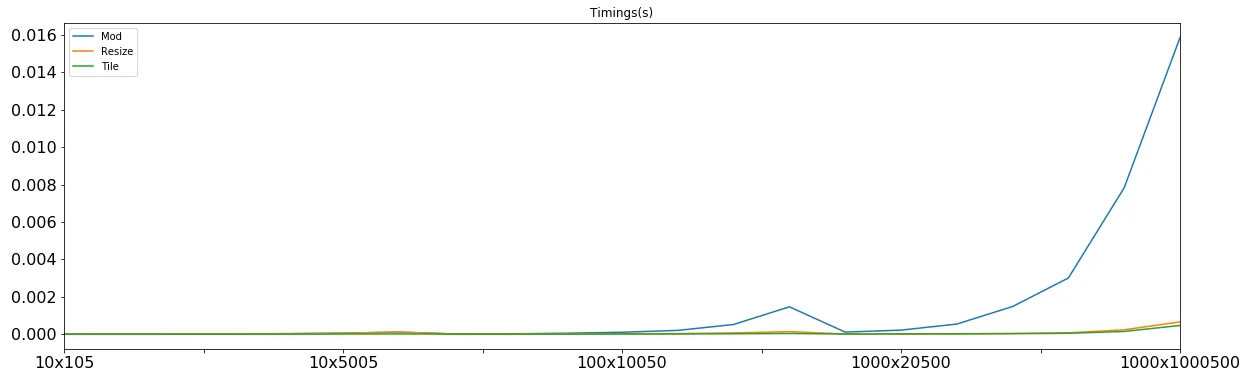
resize 和 tile 相关的表现都不错。
比较 resize 和 tile
让我们只绘制这两个:
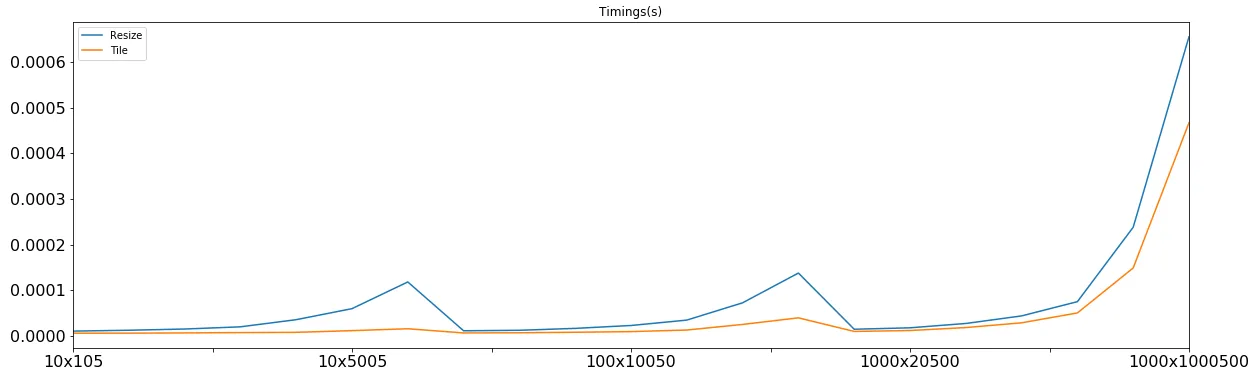
tile 在这两者之间表现得更好。
现在,让我们按照三个不同的 m's 将时间划分为块来学习:
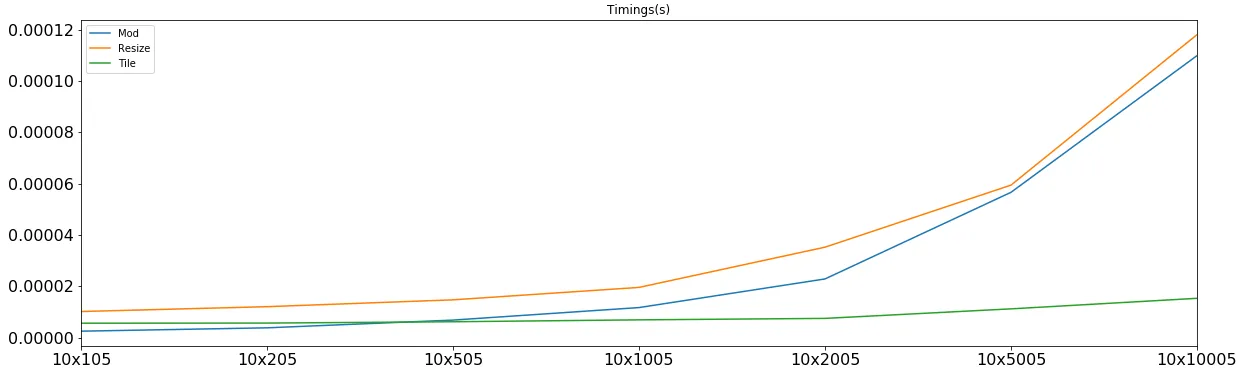
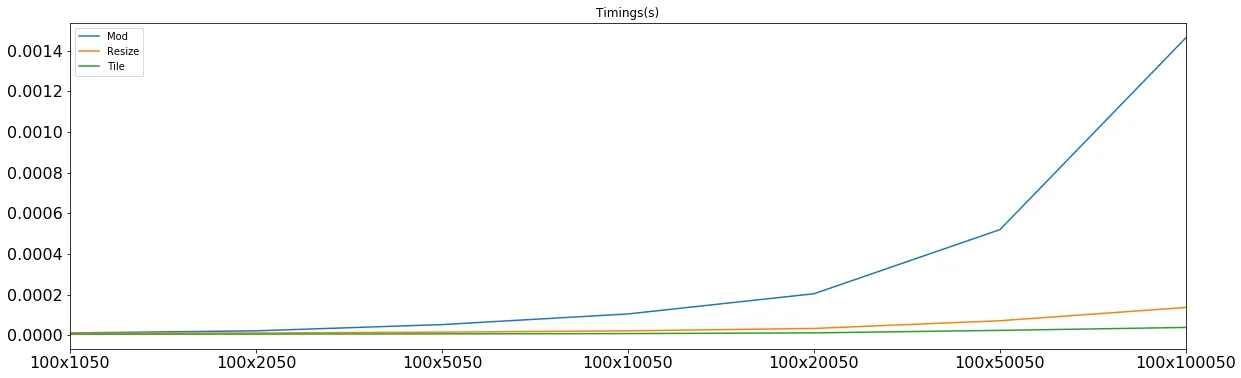
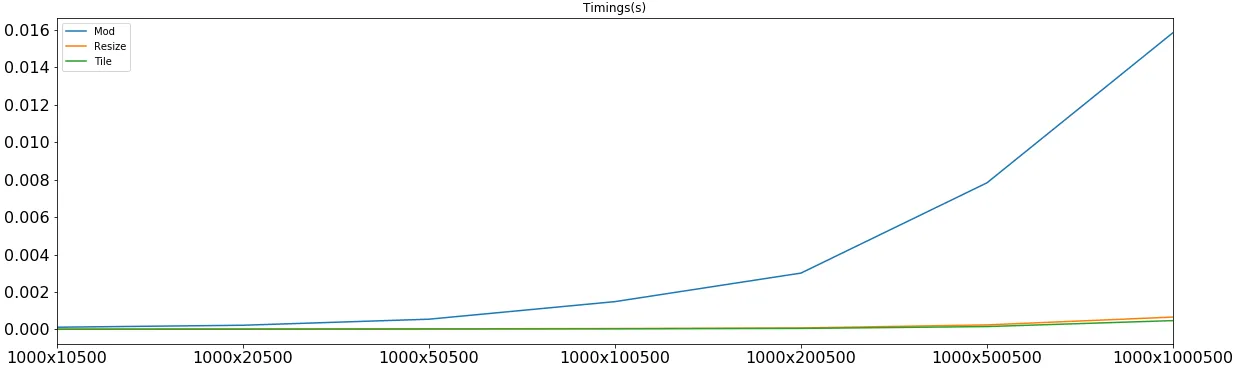
mod based one 只在小的 m 和小的 n 上获胜,而且这些 m 和 n 的计时是在 5-6 微秒左右,但在大多数其他情况下都会输掉,并且是与它相关的计算使其失去优势。
既然您要求最快的可能性,那么提供一些测试时间就很好了。因此,我使用timeit模块测试了大部分发布的代码片段。
为了更轻松地调用timeit,定义了快速函数。
def list_comp(m, n):
return [np.mod(i, m) for i in np.arange(n)]
def leftover(m, n):
nb_cycles = n//m
leftover = n-m*nb_cycles
indices = list(range(m))*nb_cycles + list(range(leftover))
def islice_cycle(m, n):
return list(islice(cycle(range(m)), n))
def npmod(m, n):
return mod(np.arange(m), n)
def resized(m, n):
return np.resize(np.arange(m), n)
测试环境:
timer = timeit.Timer(stmt="function_name(7, 12)", globals=globals()).repeat(repeat=100, number =10000)
print(f'Min: {min(timer):.6}s,\n Avg: {np.average(timer):.6}s')
Results
| Function | Minimum | Average |
|:---------------|------------:|:------------:|
| list_comp | 0.156117s | 0.160433s |
| islice_cycle | 0.00712442s | 0.00726821s |
| npmod | 0.0118933s | 0.0123122s |
| leftover | 0.00943538s | 0.00964464s |
| resized | 0.0818617s | 0.0851646s |
@Austin使用islice和cycle的答案目前是最快的。@T.Lucas稍微慢一点,但仅仅是一点点,对于纯Python来说非常快。
其他答案要慢一个数量级。
nb_cycles = n//m
leftover = n-m*nb_cycles
indices = list(range(m))*nb_cycles + list(range(leftover))