在LSTM网络(Understanding LSTMs)中,为什么输入门和输出门使用tanh函数?
{kind=link}
这背后的直觉是什么?
这只是一种非线性转换吗?如果是这样,我能否把它们都改成另一个激活函数(例如ReLU)?
在LSTM网络(Understanding LSTMs)中,为什么输入门和输出门使用tanh函数?
这背后的直觉是什么?
这只是一种非线性转换吗?如果是这样,我能否把它们都改成另一个激活函数(例如ReLU)?
sigmoid(z) = 1 / (1 + exp(-z))sigmoid'(z) = -exp(-z) / 1 + exp(-z)^2(1) The sigmoid function has all the fundamental properties of a good activation function.
双曲正切函数
数学表达式:tanh(z) = [exp(z) - exp(-z)] / [exp(z) + exp(-z)]
一阶导数:tanh'(z) = 1 - ([exp(z) - exp(-z)] / [exp(z) + exp(-z)])^2 = 1 - tanh^2(z)
优点:
(1) Often found to converge faster in practice
(2) Gradient computation is less expensive
硬切线
数学表达式:hardtanh(z) = -1(z < -1); z (-1 <= z <= 1); 1(z > 1)
一阶导数:hardtanh'(z) = 1 (-1 <= z <= 1); 0(其他情况)
优点:
(1) Computationally cheaper than Tanh
(2) Saturate for magnitudes of z greater than 1
ReLU
数学表达式:relu(z) = max(z, 0)
一阶导数:relu'(z) = 1(如果 z > 0);0(否则)
优点:
(1) Does not saturate even for large values of z
(2) Found much success in computer vision applications
Leaky ReLU
数学表达式:leaky(z) = max(z, k dot z),其中 0 < k < 1
一阶导数:relu'(z) = 如果 z > 0,则为 1;否则为 k
优点:
(1) Allows propagation of error for non-positive z which ReLU doesn't
这篇论文介绍了一些有趣的激活函数,你可以考虑阅读它。
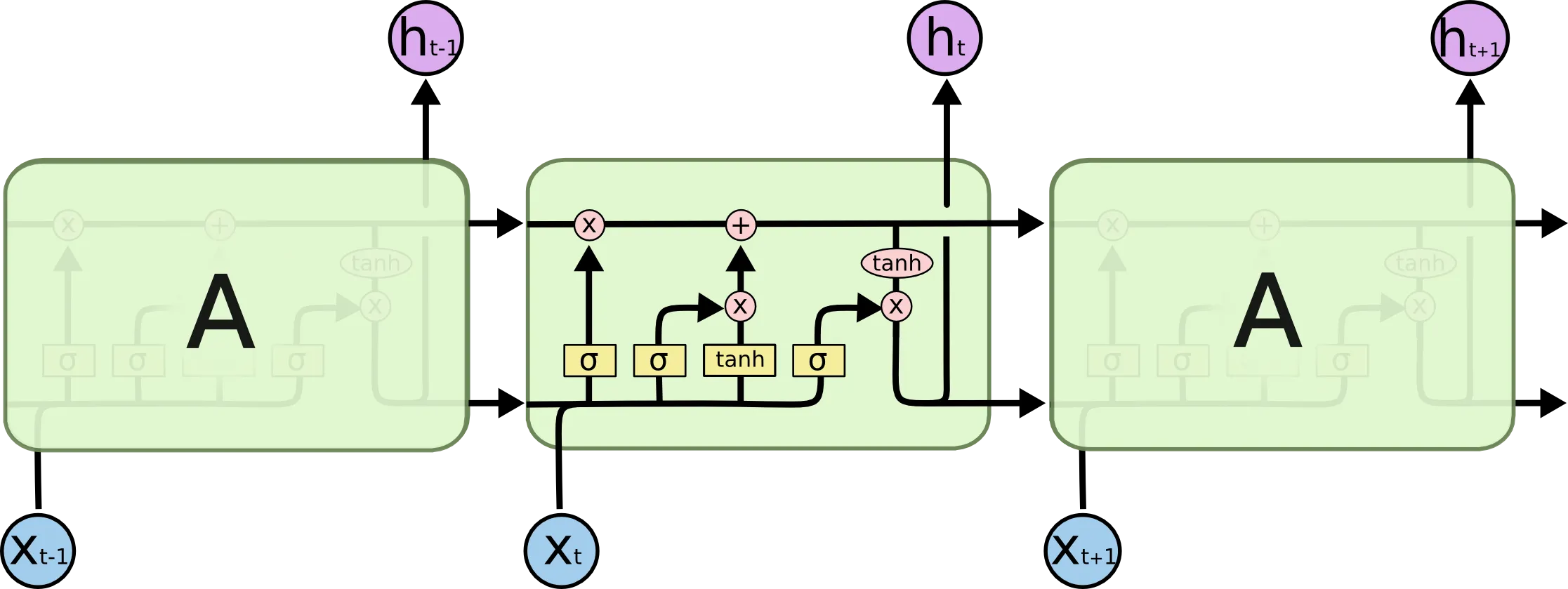
LSTMs管理一个内部状态向量,它的值应该能够在添加某些函数的输出时增加或减少。Sigmoid输出始终为非负数;状态中的值只会增加。tanh的输出可以是正数或负数,允许状态增加和减少。
这就是为什么使用tanh来确定要添加到内部状态的候选值。LSTM的GRU表亲没有第二个tanh,因此在某种意义上,第二个不是必要的。有关更多信息,请查看Chris Olah的Understanding LSTM Networks中的图表和说明。
相关问题“为什么在LSTM中使用Sigmoids?”的答案也基于函数的可能输出进行了回答:“门控”通过将数字乘以介于零和一之间的数字来实现,这就是sigmoid的输出。
Sigmoid和tanh的导数之间实际上没有实质性区别;tanh只是一个重新缩放和移位的sigmoid:请参见Richard Socher的神经网络技巧和窍门。如果二阶导数相关,请告诉我如何处理。
i_{t})和输出门(o_{t})都使用sigmoid函数。tanh激活函数用于确定候选单元状态(内部状态)值(\tilde{C}_{t})并更新隐藏状态(h_{t})。 - ARAT