我在我的Macbook Pro上安装了带有GeForce GT 750M的tensorflow 1.0.1 GPU版本。也安装了CUDA 8.0.71和cuDNN 5.1。我正在运行一段使用非CPU tensorflow正常工作的tf代码,但是在GPU版本上,我遇到了这个错误(偶尔也能正常工作):
name: GeForce GT 750M
major: 3 minor: 0 memoryClockRate (GHz) 0.9255
pciBusID 0000:01:00.0
Total memory: 2.00GiB
Free memory: 67.48MiB
I tensorflow/core/common_runtime/gpu/gpu_device.cc:906] DMA: 0
I tensorflow/core/common_runtime/gpu/gpu_device.cc:916] 0: Y
I tensorflow/core/common_runtime/gpu/gpu_device.cc:975] Creating TensorFlow device (/gpu:0) -> (device: 0, name: GeForce GT 750M, pci bus id: 0000:01:00.0)
E tensorflow/stream_executor/cuda/cuda_driver.cc:1002] failed to allocate 67.48M (70754304 bytes) from device: CUDA_ERROR_OUT_OF_MEMORY
Training...
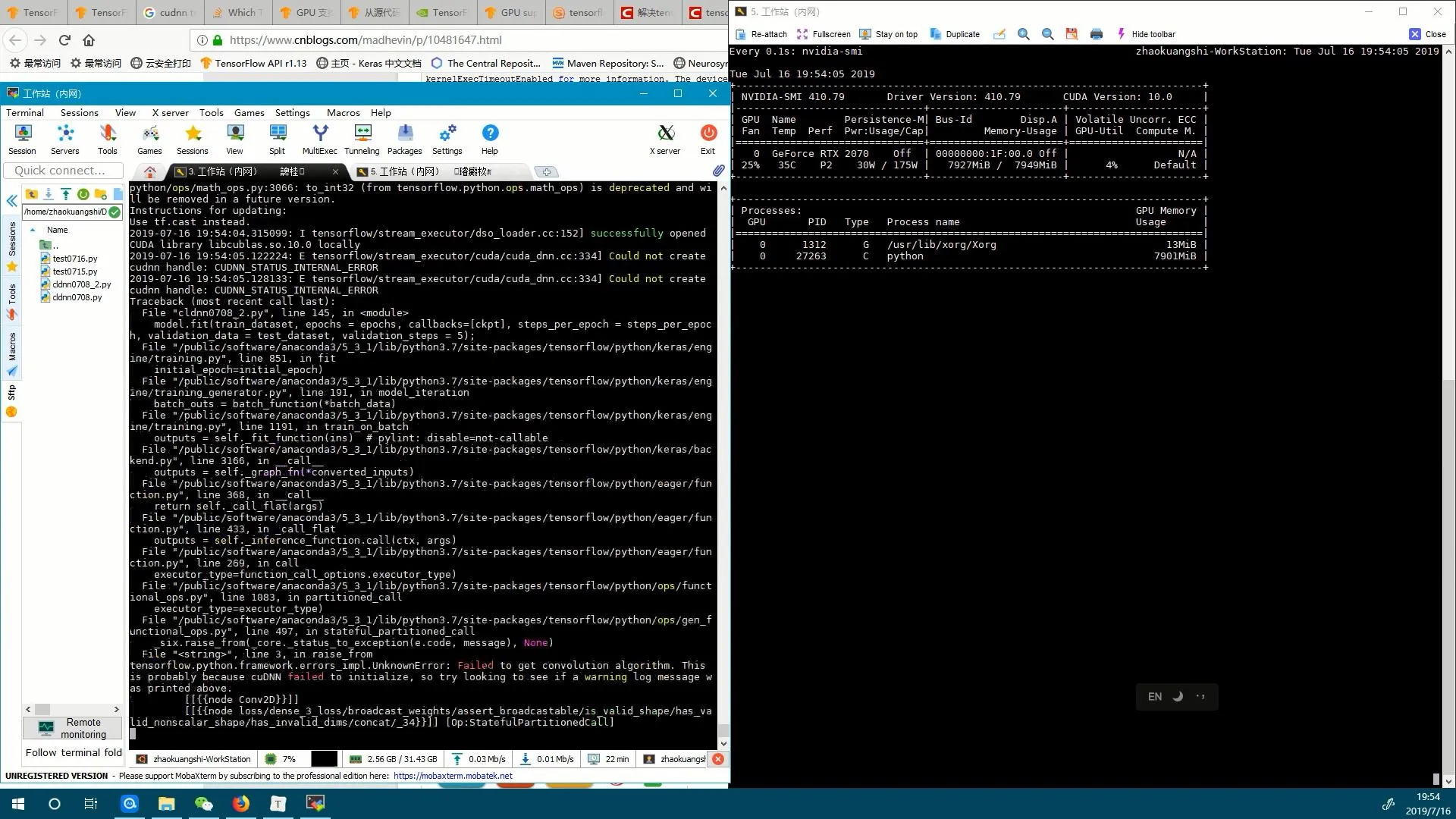
E tensorflow/stream_executor/cuda/cuda_dnn.cc:397] could not create cudnn handle: CUDNN_STATUS_INTERNAL_ERROR
E tensorflow/stream_executor/cuda/cuda_dnn.cc:364] could not destroy cudnn handle: CUDNN_STATUS_BAD_PARAM
F tensorflow/core/kernels/conv_ops.cc:605] Check failed: stream->parent()->GetConvolveAlgorithms(&algorithms)
Abort trap: 6
这里发生了什么?这是tensorflow的一个bug吗?请帮忙。
当我运行python代码时,这是GPU内存空间:
Device 0 [PCIe 0:1:0.0]: GeForce GT 750M (CC 3.0): 83.477 of 2047.6 MB (i.e. 4.08%) Free
MacBook-Pro:cuda-smi-master xxxxxx$ ./cuda-smi
Device 0 [PCIe 0:1:0.0]: GeForce GT 750M (CC 3.0): 83.477 of 2047.6 MB (i.e. 4.08%) Free
MacBook-Pro:cuda-smi-master xxxxxx$ ./cuda-smi
Device 0 [PCIe 0:1:0.0]: GeForce GT 750M (CC 3.0): 83.477 of 2047.6 MB (i.e. 4.08%) Free
MacBook-Pro:cuda-smi-master xxxxxx$ ./cuda-smi
Device 0 [PCIe 0:1:0.0]: GeForce GT 750M (CC 3.0): 1.1016 of 2047.6 MB (i.e. 0.0538%) Free
MacBook-Pro:cuda-smi-master xxxxxx$ ./cuda-smi
Device 0 [PCIe 0:1:0.0]: GeForce GT 750M (CC 3.0): 1.1016 of 2047.6 MB (i.e. 0.0538%) Free
MacBook-Pro:cuda-smi-master xxxxxx$ ./cuda-smi
Device 0 [PCIe 0:1:0.0]: GeForce GT 750M (CC 3.0): 1.1016 of 2047.6 MB (i.e. 0.0538%) Free
MacBook-Pro:cuda-smi-master xxxxxx$ ./cuda-smi
Device 0 [PCIe 0:1:0.0]: GeForce GT 750M (CC 3.0): 1.1016 of 2047.6 MB (i.e. 0.0538%) Free
MacBook-Pro:cuda-smi-master xxxxxx$ ./cuda-smi
Device 0 [PCIe 0:1:0.0]: GeForce GT 750M (CC 3.0): 91.477 of 2047.6 MB (i.e. 4.47%) Free
MacBook-Pro:cuda-smi-master xxxxxx$ ./cuda-smi
Device 0 [PCIe 0:1:0.0]: GeForce GT 750M (CC 3.0): 22.852 of 2047.6 MB (i.e. 1.12%) Free
MacBook-Pro:cuda-smi-master xxxxxx$ ./cuda-smi
Device 0 [PCIe 0:1:0.0]: GeForce GT 750M (CC 3.0): 22.852 of 2047.6 MB (i.e. 1.12%) Free
MacBook-Pro:cuda-smi-master xxxxxx$ ./cuda-smi
Device 0 [PCIe 0:1:0.0]: GeForce GT 750M (CC 3.0): 36.121 of 2047.6 MB (i.e. 1.76%) Free
MacBook-Pro:cuda-smi-master xxxxxx$ ./cuda-smi
Device 0 [PCIe 0:1:0.0]: GeForce GT 750M (CC 3.0): 71.477 of 2047.6 MB (i.e. 3.49%) Free
MacBook-Pro:cuda-smi-master xxxxxx$ ./cuda-smi
Device 0 [PCIe 0:1:0.0]: GeForce GT 750M (CC 3.0): 67.477 of 2047.6 MB (i.e. 3.3%) Free
MacBook-Pro:cuda-smi-master xxxxxx$ ./cuda-smi
Device 0 [PCIe 0:1:0.0]: GeForce GT 750M (CC 3.0): 67.477 of 2047.6 MB (i.e. 3.3%) Free
MacBook-Pro:cuda-smi-master xxxxxx$ ./cuda-smi
Device 0 [PCIe 0:1:0.0]: GeForce GT 750M (CC 3.0): 67.477 of 2047.6 MB (i.e. 3.3%) Free
{kind=link}