groupby 中的 .T
def tgrp(df):
df = df.drop('Name', axis=1)
return df.reset_index(drop=True).T
df2.groupby('Name').apply(tgrp).unstack()
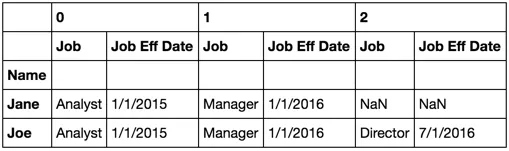
解释
groupby 返回一个包含原始系列或数据帧已被分组信息的对象。我们可以先将 df2.groupby('Name') 分配给一个变量(我经常这样做),比如说 gb,而不是执行一个后续的操作。
gb = df2.groupby('Name')
在这个对象
gb上,我们可以调用
.mean()来获取每个组的平均值。或者使用
.last()来获取每个组的最后一个元素(行)。或者使用
.transform(lambda x: (x - x.mean()) / x.std())在每个组内获取zscore转换。当您想要在组内执行没有预定义函数的操作时,仍然可以使用
.apply()。
对于
groupby对象的
.apply()与
dataframe的不同。对于数据框,
.apply()以可调用对象作为其参数,并将该可调用对象应用于对象中的每个列(或行)。传递给该可调用对象的对象是
pd.Series。当您在
dataframe上下文中使用
.apply时,牢记这一点非常有帮助。在
groupby对象的上下文中,传递给可调用参数的对象是数据框。实际上,该数据框是由
groupby指定的其中一个组。
当我编写这样的函数来传递给
groupby.apply时,通常将参数定义为
df以反映它是一个数据帧。
好的,所以我们有:
df2.groupby('Name').apply(tgrp)
这将为每个'Name'生成一个子数据框,并将该子数据框传递给函数tgrp。然后,groupby对象会重新组合所有经过tgrp函数处理的组。
效果如下。
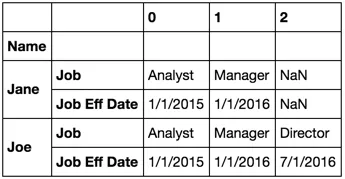
我将原作者的简单转置尝试认真对待了,但首先我需要做一些事情。如果我只是这样做了:
df2[df2.Name == 'Jane'].T
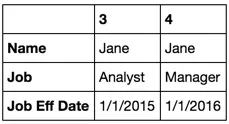
df2[df2.Name == 'Joe'].T
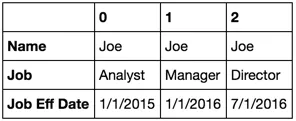
手动合并这些(不使用groupby):
pd.concat([df2[df2.Name == 'Jane'].T, df2[df2.Name == 'Joe'].T])
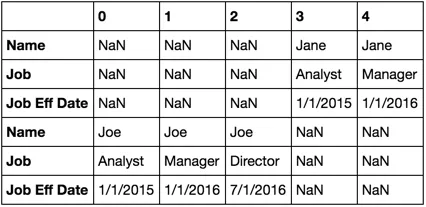
哇!这太丑了。显然,[0, 1, 2]的索引值与[3, 4]不匹配。因此,让我们重置。
pd.concat([df2[df2.Name == 'Jane'].reset_index(drop=True).T,
df2[df2.Name == 'Joe'].reset_index(drop=True).T])
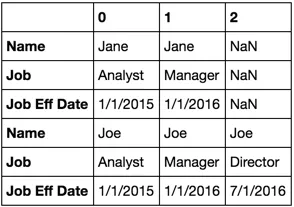
这样就好多了。但现在我们进入了 groupby 应该处理的领域,所以让它来处理吧。
回到
df2.groupby('Name').apply(tgrp)
这里唯一缺失的是我们需要取消堆叠结果以获得所需的输出。

df2[df2.Name == 'Jane']并在其上运行tgrp。像这样:tgrp(df2[df2.Name == 'Jane'])。观察tgrp前后的df2[df2.Name == 'Jane'],看看是否有帮助。 - piRSquared