我很惊讶没有人谈论这个:使用scikit learn和numpy中的polyfit进行多项式回归的差异。
首先,我们来看数据:
然后您可以创建一个图表。
首先,我们来看数据:
xdic={'X': {11: 300, 12: 170, 13: 288, 14: 360, 15: 319, 16: 330, 17: 520, 18: 345, 19: 399, 20: 479}}
ydic={'y': {11: 305000, 12: 270000, 13: 360000, 14: 370000, 15: 379000, 16: 405000, 17: 407500, 18: 450000, 19: 450000, 20: 485000}}
X=pd.DataFrame.from_dict(xdic)
y=pd.DataFrame.from_dict(ydic)
import numpy as np
X_seq = np.linspace(X.min(),X.max(),300).reshape(-1,1)
那么让我们使用scikit-learn创建模型
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import make_pipeline
from sklearn.linear_model import LinearRegression
degree=9
polyreg=make_pipeline(PolynomialFeatures(degree),
LinearRegression())
polyreg.fit(X,y)
然后您可以创建一个图表。
plt.figure()
plt.scatter(X,y)
plt.plot(X_seq,polyreg.predict(X_seq),color="black")
plt.xlabel('X')
plt.ylabel('y')
plt.show()
这里是情节。
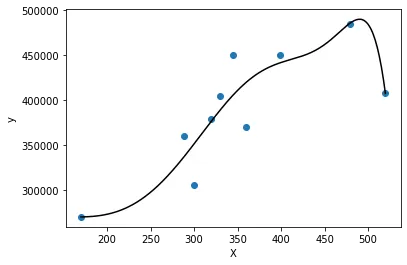
使用numpy,情况就很不同了。
coefs = np.polyfit(X.values.flatten(), y.values.flatten(), 9)
X_seq = np.linspace(X.min(),X.max(),300)
plt.figure()
plt.plot(X_seq, np.polyval(coefs, X_seq), color="black")
plt.scatter(X,y)
plt.show()
通过这个图表,我们可以看到结果有很大的不同。
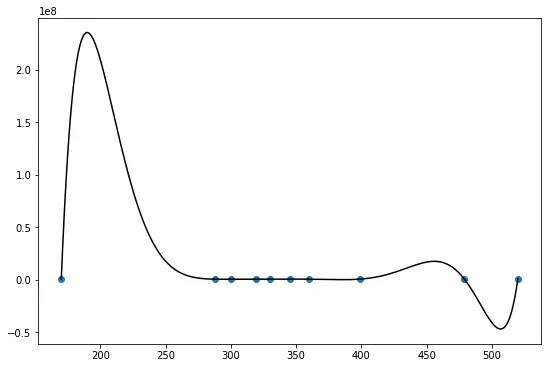
可能是由于浮点数精度问题导致的...