{kind=link}
我想要处理PDF文件,特别是其中的表格。我编写了以下代码:
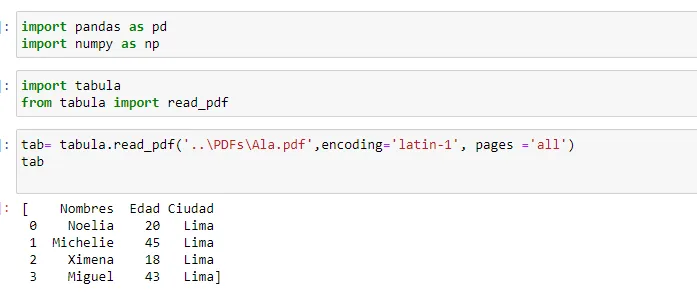
import pandas as pd
import numpy as np
import tabula
from tabula import read_pdf
tab= tabula.read_pdf('..\PDFs\Ala.pdf',encoding='latin-1', pages ='all')
tab
但我得到了一个值的列表,像这样:
[ Nombres Edad Ciudad
0 Noelia 20 Lima
1 Michelie 45 Lima
2 Ximena 18 Lima
3 Miguel 43 Lima]
我无法对其进行分析,因为它不是数据框架。这只是一个例子,真实的PDF文件包含文本和多个页面之间的表格。
所以,请有人帮我解决这个问题吗?
print(type(tab))显示什么? - Martin Evanstab[0]可能是一个数据框。 - Martin Evans