我想对Dataframe中的几列应用一个小方法。方法color_negative不能应用于包含字符串的列,因此我需要以某种方式跳过这些列。我可以想到两种方法来解决这个问题,但可悲的是都没有起作用。
在第一种方法中: 我尝试使用Dataframe的索引和将while循环的递增计数器设置为1,逐个跳过第一列,然后对每一列应用该方法。当执行此方法时,我会得到错误,即'Series'对象没有'style'属性,因此显然无法将方法应用于单个列。
在第二种方法中: 我尝试使用subset仅将该方法应用于具有数字值的列,但我不确定是否正确使用了subset。当执行此方法时,我会得到错误,即类型为'Styler'的对象没有len()。
下面是一个简化的示例:
在第一种方法中: 我尝试使用Dataframe的索引和将while循环的递增计数器设置为1,逐个跳过第一列,然后对每一列应用该方法。当执行此方法时,我会得到错误,即'Series'对象没有'style'属性,因此显然无法将方法应用于单个列。
在第二种方法中: 我尝试使用subset仅将该方法应用于具有数字值的列,但我不确定是否正确使用了subset。当执行此方法时,我会得到错误,即类型为'Styler'的对象没有len()。
下面是一个简化的示例:
import pandas as pd
d = {'col1': ['a', 'b'], 'col2': [21, 22], 'col3': [3, 51]}
df = pd.DataFrame(data=d)
def color_negative_red(val):
color = 'black'
if val < -1 : color = 'red'
if val > 1 : color = 'green'
return 'color: %s' % color
i=1
while i <= len(df):
#Approach 1
df.iloc[:, i] = df.iloc[:, i].style.applymap(color_negative_red)
#Approach 2
df = df.style.applymap(color_negative_red, subset = df.iloc[:, i])
i+=1
df
有人有解决这个问题的建议吗?
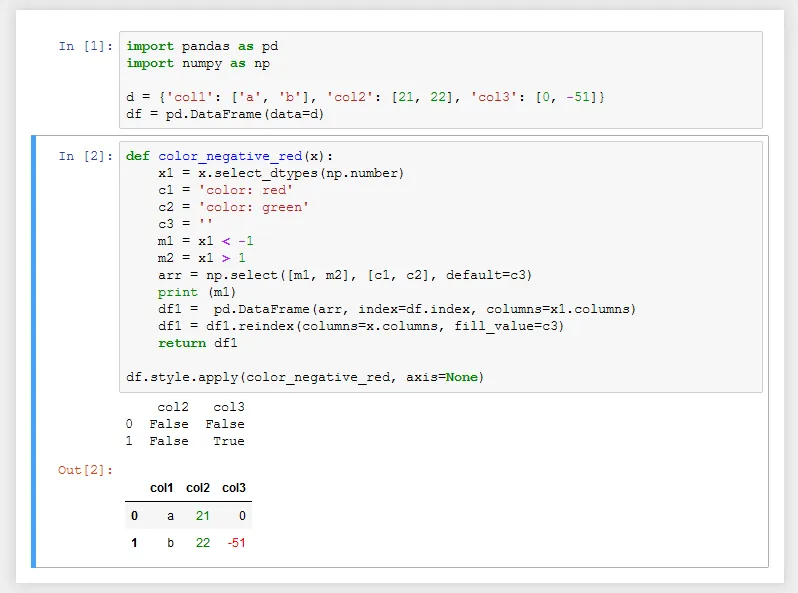
df.select_dtype函数来获取特定数据类型的列,例如df.select_dtype(include=np.number)。 - Scott Bostondf._get_numeric_data()- sacuL