如果您只想要模块,可以运行代码并通过sys.modules在您的包中查找任何模块。
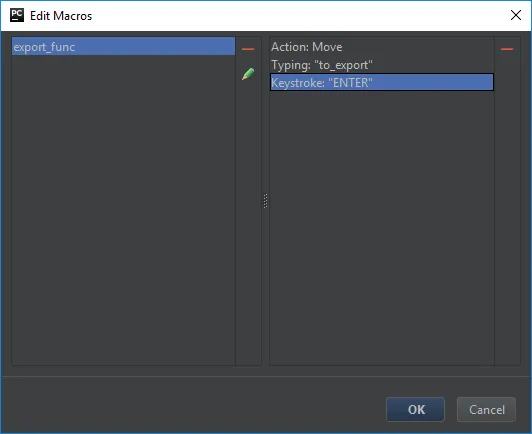
要将所有依赖项移动到PyCharm中,您可以创建一个宏,将突出显示的对象移动到预定义文件中,并将宏附加到键盘快捷方式,然后快速递归地移动任何项目内导入。例如,我创建了一个名为export_func的宏,将函数移动到to_export.py中,并添加了F10的快捷方式:
给定一个要移动的函数,例如:
from utils import factorize
def my_func():
print(factorize(100))
以及 utils.py 看起来像这样
import numpy as np
from collections import Counter
import sys
if sys.version_info.major >= 3:
from functools import lru_cache
else:
from functools32 import lru_cache
PREPROC_CAP = int(1e6)
@lru_cache(10)
def get_primes(n):
n = int(n)
sieve = np.ones(n // 3 + (n % 6 == 2), dtype=np.bool)
for i in range(1, int(n ** 0.5) // 3 + 1):
if sieve[i]:
k = 3 * i + 1 | 1
sieve[k * k // 3::2 * k] = False
sieve[k * (k - 2 * (i & 1) + 4) // 3::2 * k] = False
return list(map(int, np.r_[2, 3, ((3 * np.nonzero(sieve)[0][1:] + 1) | 1)]))
@lru_cache(10)
def _get_primes_set(n):
return set(get_primes(n))
@lru_cache(int(1e6))
def factorize(value):
if value == 1:
return Counter()
if value < PREPROC_CAP and value in _get_primes_set(PREPROC_CAP):
return Counter([value])
for p in get_primes(PREPROC_CAP):
if p ** 2 > value:
break
if value % p == 0:
factors = factorize(value // p).copy()
factors[p] += 1
return factors
for p in range(PREPROC_CAP + 1, int(value ** .5) + 1, 2):
if value % p == 0:
factors = factorize(value // p).copy()
factors[p] += 1
return factors
return Counter([value])
我可以将my_func高亮并按下F10键创建to_export.py:
from utils import factorize
def my_func():
print(factorize(100))
突出显示`to_export.py`中的`factorize`,并按下F10键即可。
from collections import Counter
from functools import lru_cache
from utils import PREPROC_CAP, _get_primes_set, get_primes
def my_func():
print(factorize(100))
@lru_cache(int(1e6))
def factorize(value):
if value == 1:
return Counter()
if value < PREPROC_CAP and value in _get_primes_set(PREPROC_CAP):
return Counter([value])
for p in get_primes(PREPROC_CAP):
if p ** 2 > value:
break
if value % p == 0:
factors = factorize(value // p).copy()
factors[p] += 1
return factors
for p in range(PREPROC_CAP + 1, int(value ** .5) + 1, 2):
if value % p == 0:
factors = factorize(value // p).copy()
factors[p] += 1
return factors
return Counter([value])
然后将PREPROC_CAP、_get_primes_set和get_primes进行突出显示,然后按F10键得到:
from collections import Counter
from functools import lru_cache
import numpy as np
def my_func():
print(factorize(100))
@lru_cache(int(1e6))
def factorize(value):
if value == 1:
return Counter()
if value < PREPROC_CAP and value in _get_primes_set(PREPROC_CAP):
return Counter([value])
for p in get_primes(PREPROC_CAP):
if p ** 2 > value:
break
if value % p == 0:
factors = factorize(value // p).copy()
factors[p] += 1
return factors
for p in range(PREPROC_CAP + 1, int(value ** .5) + 1, 2):
if value % p == 0:
factors = factorize(value // p).copy()
factors[p] += 1
return factors
return Counter([value])
PREPROC_CAP = int(1e6)
@lru_cache(10)
def _get_primes_set(n):
return set(get_primes(n))
@lru_cache(10)
def get_primes(n):
n = int(n)
sieve = np.ones(n // 3 + (n % 6 == 2), dtype=np.bool)
for i in range(1, int(n ** 0.5) // 3 + 1):
if sieve[i]:
k = 3 * i + 1 | 1
sieve[k * k // 3::2 * k] = False
sieve[k * (k - 2 * (i & 1) + 4) // 3::2 * k] = False
return list(map(int, np.r_[2, 3, ((3 * np.nonzero(sieve)[0][1:] + 1) | 1)]))
即使你要复制很多代码,它也会非常快。
from mymodule import func导入函数,并且不使用任何全局变量或重复任何函数名称,则可能可以安全地将所有函数收集到单个脚本中。如果您通常使用import mymodule然后mymodule.func(),那么您可以让脚本创建每个模块的 shell 版本,只包含相关函数。 - Matthias Fripp