关于神经网络反向传播算法的编码,我有几个问题:
我的网络拓扑结构是输入层、隐藏层和输出层。隐藏层和输出层都有sigmoid函数。
- 首先,我应该使用偏置吗? 在我的网络中,偏置应连接到哪里? 我应该在隐藏层和输出层中每层放置一个偏置单元吗? 那输入层呢?
- 在这个链接中,他们将最后一个delta定义为输入-输出,然后像图中所示回传delta。他们保留了一张表来存放所有的delta,然后以前馈方式实际传播误差。这是否与标准的反向传播算法不同?
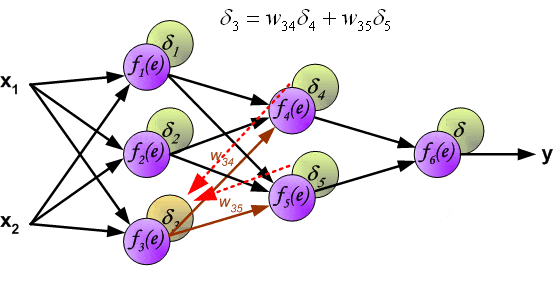
- 我应该逐渐降低学习因子吗?
- 如果有人知道,Resilient Propagation是在线学习还是批量学习技术?
谢谢
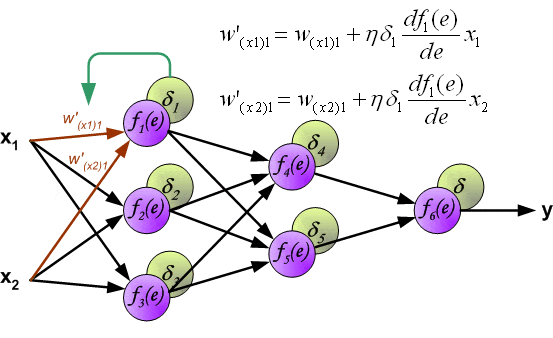
编辑:还有一件事。在下面的图片中,假设我使用sigmoid函数,d f1(e) / de是f1(e) * [1- f1(e)],对吗?
- 我认为RP可以在线或批处理。
- Richard H