我正在按照DataCamp课程的指南使用XGBoost分类技术。数据的处理如下:
X, y = df.iloc[:,:-1], df.iloc[:,-1]
# Create a boolean mask for categorical columns: check if df.dtypes == object
categorical_mask = (X.dtypes == object)
# Get list of categorical column names
categorical_columns = X.columns[categorical_mask].tolist()
# Create LabelEncoder object: le
le = LabelEncoder()
# Apply LabelEncoder to categorical columns
X[categorical_columns] = X[categorical_columns].apply(lambda x: le.fit_transform(x))
# Create OneHotEncoder: ohe
ohe = OneHotEncoder(categorical_features=categorical_mask, sparse=False)
# Apply OneHotEncoder to categorical columns - output is no longer a dataframe: df_encoded is a NumPy array
X_encoded = ohe.fit_transform(X)
testy = pd.DataFrame(X_encoded)
X_train, X_test, y_train, y_test= train_test_split(testy, y, test_size=0.2, random_state=123)
DM_train = xgb.DMatrix(X_train, label = y_train, )
DM_test = xgb.DMatrix(X_test, label = y_test)
我使用交叉验证的网格搜索调整了超参数,并使用x_train和y_train来拟合模型。
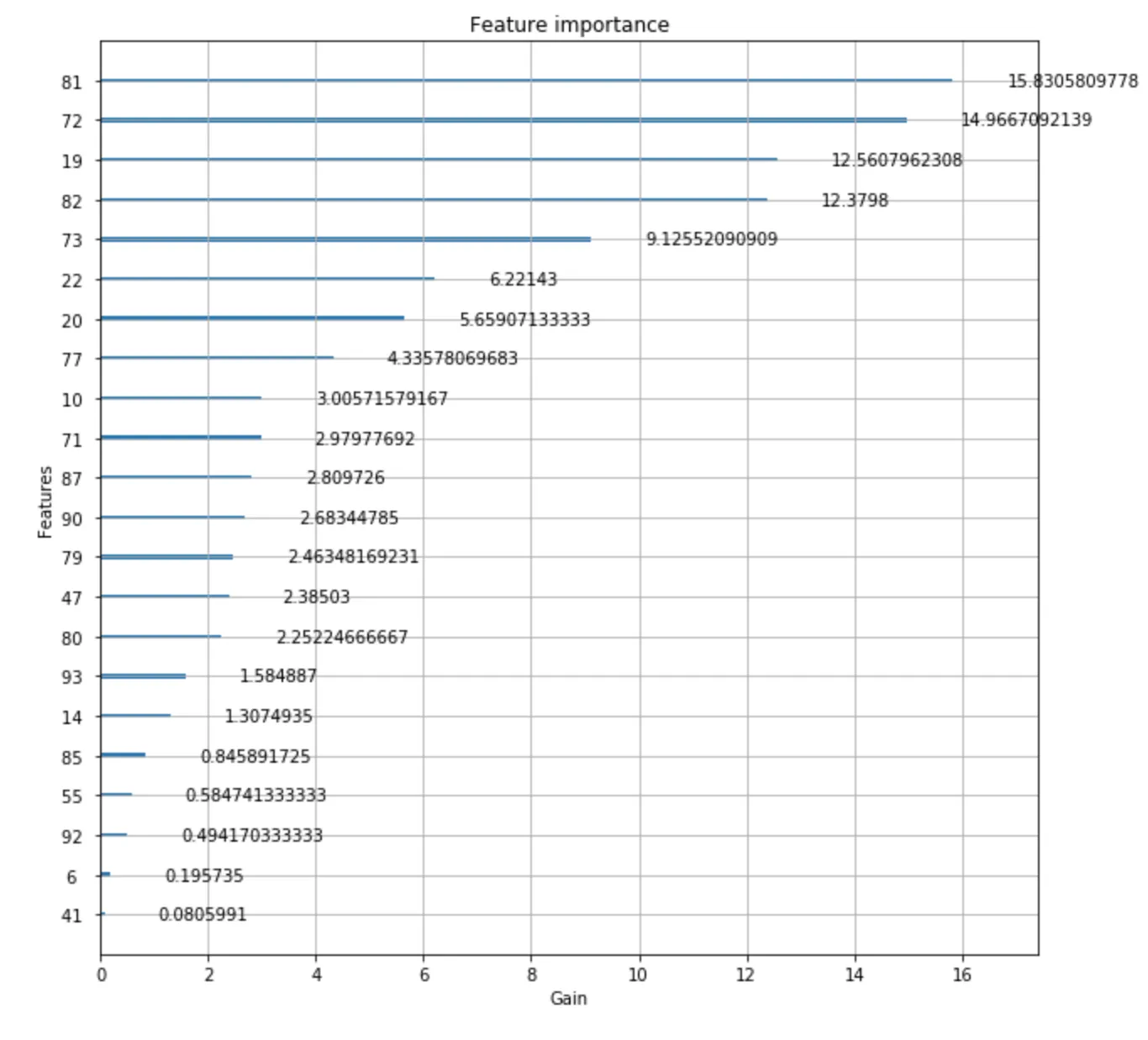
我使用调整后的参数拟合模型,然后创建了特征重要性图:
model.fit(X_train,y_train)
xgb.plot_importance(model, importance_type = 'gain')
这是输出结果:

非常感谢您的任何帮助。