在Coursera上,斯坦福大学的Andrew Ng在机器学习的介绍课程中给出了一个幻灯片,其中提供了以下一行Octave解决方案,以解决鸡尾酒会问题,假设音频源由两个空间分离的麦克风录制:
在幻灯片底部标注着“来源:Sam Roweis、Yair Weiss、Eero Simoncelli”,而在早期的幻灯片底部则标注着“音频剪辑由Te-Won Lee提供”。在视频中,Ng教授说:
“So you might look at unsupervised learning like this and ask, 'How complicated is it to implement this?' It seems like in order to build this application, it seems like to do this audio processing, you would write a ton of code, or maybe link into a bunch of C++ or Java libraries that process audio. It seems like it would be a really complicated program to do this audio: separating out audio and so on. It turns out the algorithm to do what you just heard, that can be done with just one line of code ... shown right here. It did take researchers a long time to come up with this line of code. So I'm not saying this is an easy problem. But it turns out that when you use the right programming environment many learning algorithms will be really short programs."
视频演示的分离音频结果并不完美,但在我看来仍然非常惊人。有人对这一行代码是如何表现得如此出色有任何见解吗?特别是,有人知道Te-Won Lee、Sam Roweis、Yair Weiss和Eero Simoncelli关于这一行代码的工作的参考资料吗?
更新:
为了展示该算法对麦克风分离距离的敏感性,以下Octave模拟将两个空间分离的音调发生器的音调分离出来。
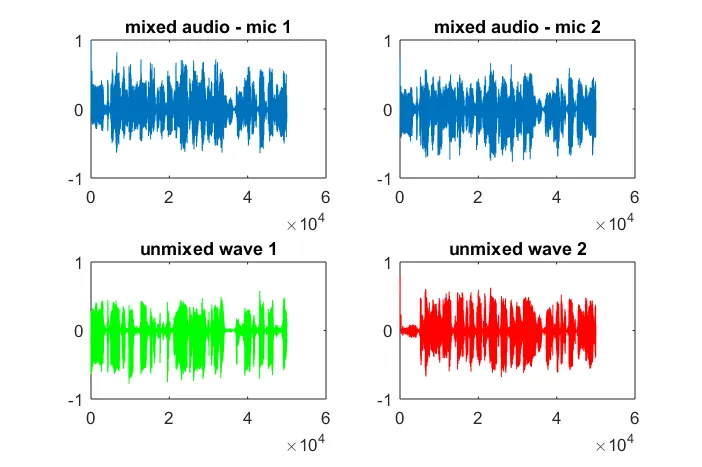
在我的笔记本电脑上执行约10分钟后,模拟生成了以下三个图示,说明两个隔离的音调具有正确的频率。然而,将麦克风分离距离设置为零(即dMic=0)会导致模拟生成以下三个图示,说明模拟无法隔离第二个音调(通过svd的s矩阵返回的单个显著对角线项进行确认)。我希望智能手机上的麦克风分离距离足够大以产生良好的结果,但将麦克风分离距离设置为5.25英寸(即dMic=0.1333米)会导致模拟生成以下不太令人鼓舞的图示,说明第一个隔离音调中存在更高频率的成分。
[W,s,v]=svd((repmat(sum(x.*x,1),size(x,1),1).*x)*x');
在幻灯片底部标注着“来源:Sam Roweis、Yair Weiss、Eero Simoncelli”,而在早期的幻灯片底部则标注着“音频剪辑由Te-Won Lee提供”。在视频中,Ng教授说:
“So you might look at unsupervised learning like this and ask, 'How complicated is it to implement this?' It seems like in order to build this application, it seems like to do this audio processing, you would write a ton of code, or maybe link into a bunch of C++ or Java libraries that process audio. It seems like it would be a really complicated program to do this audio: separating out audio and so on. It turns out the algorithm to do what you just heard, that can be done with just one line of code ... shown right here. It did take researchers a long time to come up with this line of code. So I'm not saying this is an easy problem. But it turns out that when you use the right programming environment many learning algorithms will be really short programs."
视频演示的分离音频结果并不完美,但在我看来仍然非常惊人。有人对这一行代码是如何表现得如此出色有任何见解吗?特别是,有人知道Te-Won Lee、Sam Roweis、Yair Weiss和Eero Simoncelli关于这一行代码的工作的参考资料吗?
更新:
为了展示该算法对麦克风分离距离的敏感性,以下Octave模拟将两个空间分离的音调发生器的音调分离出来。
% define model
f1 = 1100; % frequency of tone generator 1; unit: Hz
f2 = 2900; % frequency of tone generator 2; unit: Hz
Ts = 1/(40*max(f1,f2)); % sampling period; unit: s
dMic = 1; % distance between microphones centered about origin; unit: m
dSrc = 10; % distance between tone generators centered about origin; unit: m
c = 340.29; % speed of sound; unit: m / s
% generate tones
figure(1);
t = [0:Ts:0.025];
tone1 = sin(2*pi*f1*t);
tone2 = sin(2*pi*f2*t);
plot(t,tone1);
hold on;
plot(t,tone2,'r'); xlabel('time'); ylabel('amplitude'); axis([0 0.005 -1 1]); legend('tone 1', 'tone 2');
hold off;
% mix tones at microphones
% assume inverse square attenuation of sound intensity (i.e., inverse linear attenuation of sound amplitude)
figure(2);
dNear = (dSrc - dMic)/2;
dFar = (dSrc + dMic)/2;
mic1 = 1/dNear*sin(2*pi*f1*(t-dNear/c)) + \
1/dFar*sin(2*pi*f2*(t-dFar/c));
mic2 = 1/dNear*sin(2*pi*f2*(t-dNear/c)) + \
1/dFar*sin(2*pi*f1*(t-dFar/c));
plot(t,mic1);
hold on;
plot(t,mic2,'r'); xlabel('time'); ylabel('amplitude'); axis([0 0.005 -1 1]); legend('mic 1', 'mic 2');
hold off;
% use svd to isolate sound sources
figure(3);
x = [mic1' mic2'];
[W,s,v]=svd((repmat(sum(x.*x,1),size(x,1),1).*x)*x');
plot(t,v(:,1));
hold on;
maxAmp = max(v(:,1));
plot(t,v(:,2),'r'); xlabel('time'); ylabel('amplitude'); axis([0 0.005 -maxAmp maxAmp]); legend('isolated tone 1', 'isolated tone 2');
hold off;
在我的笔记本电脑上执行约10分钟后,模拟生成了以下三个图示,说明两个隔离的音调具有正确的频率。然而,将麦克风分离距离设置为零(即dMic=0)会导致模拟生成以下三个图示,说明模拟无法隔离第二个音调(通过svd的s矩阵返回的单个显著对角线项进行确认)。我希望智能手机上的麦克风分离距离足够大以产生良好的结果,但将麦克风分离距离设置为5.25英寸(即dMic=0.1333米)会导致模拟生成以下不太令人鼓舞的图示,说明第一个隔离音调中存在更高频率的成分。
x是什么;它是波形的频谱图还是其他什么? - Isaac