我有一个场景,需要根据同一行中另一列和另一个数据框中的值转换特定列的值。
例子-
print(parent_df)
school location modifed_date
0 school_1 New Delhi 2020-04-06
1 school_2 Kolkata 2020-04-06
2 school_3 Bengaluru 2020-04-06
3 school_4 Mumbai 2020-04-06
4 school_5 Chennai 2020-04-06
print(location_df)
school location
0 school_10 New Delhi
1 school_20 Kolkata
2 school_30 Bengaluru
3 school_40 Mumbai
4 school_50 Chennai
根据这个用例,我需要根据同一DataFrame中的“location”列和“location_df”中的位置属性,转换“parent_df”中的学校名称。 为了实现这种转换,我编写了以下方法。
def transform_school_name(row, location_df):
name_alias = location_df[location_df['location'] == row['location']]
if len(name_alias) > 0:
return location_df.school.iloc[0]
else:
return row['school']
这是我调用该方法的方式
parent_df['school'] = parent_df.apply(UtilityMethods.transform_school_name, args=(self.location_df,), axis=1)
问题是,对于仅有4.6万条记录,我看到整个转换过程大约需要2分钟时间,这太慢了。我应该如何改进这个解决方案的性能?
编辑
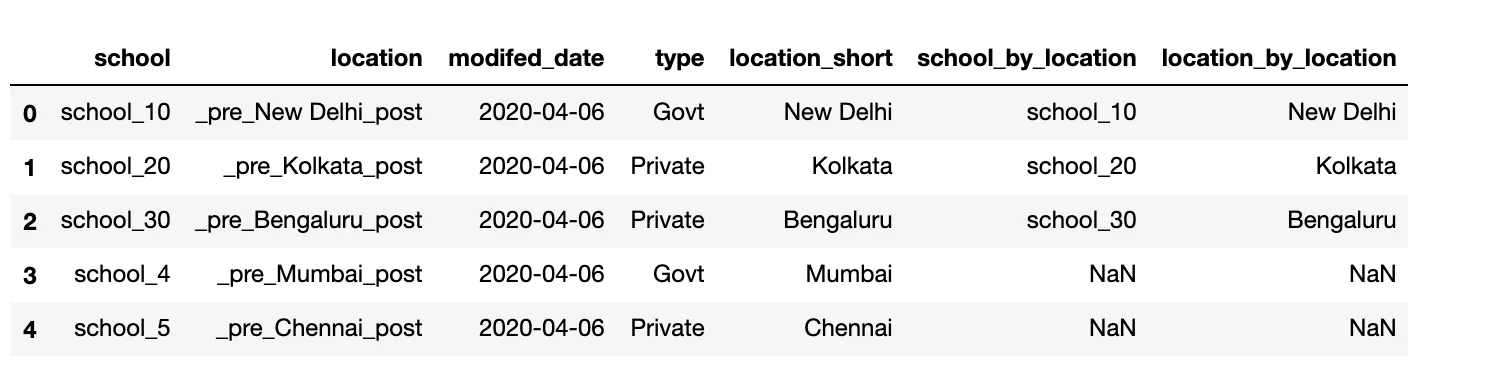
以下是我正在处理的实际情况,需要在替换原始列中的值之前进行小的转换。我不确定是否可以在下面的一个答案中提到的replace()方法内完成。print(parent_df)
school location modifed_date type
0 school_1 _pre_New Delhi_post 2020-04-06 Govt
1 school_2 _pre_Kolkata_post 2020-04-06 Private
2 school_3 _pre_Bengaluru_post 2020-04-06 Private
3 school_4 _pre_Mumbai_post 2020-04-06 Govt
4 school_5 _pre_Chennai_post 2020-04-06 Private
print(location_df)
school location type
0 school_10 New Delhi Govt
1 school_20 Kolkata Private
2 school_30 Bengaluru Private
自定义方法代码。
def transform_school_name(row, location_df):
location_values = row['location'].split('_')
name_alias = location_df[location_df['location'] == location_values[1]]
name_alias = name_alias[name_alias['type'] == location_df['type']]
if len(name_alias) > 0:
return location_df.school.iloc[0]
else:
return row['school']
def transform_school_name(row, location_df):
name_alias = location_df[location_df['location'] == row['location']]
if len(name_alias) > 0:
return location_df.school.iloc[0]
else:
return row['school']
这是我需要处理的实际情况,所以使用 replace() 方法无法帮助。
location_df中存在位置时才进行更新,因此使用replace而不是map。 - Quang Hoangreplace的作用。只更新现有的值,保留不存在的值不变。map需要额外的fillna后跟。 - Quang Hoang