我会先给出说明性的图表,类似于这样的内容:
x<-c(0.108,0.111,0.113,0.116,0.118,0.121,0.123,0.126,0.128,0.131,0.133,0.136)
y<-c(-6.908,-6.620,-5.681,-5.165,-4.690,-4.646,-3.979,-3.755,-3.564,-3.558,-3.272,-3.073)
dat <- data.frame(y=y,x=x)
library(latticeExtra)
library(grid)
xyplot(y ~ x,data=dat,par.settings = ggplot2like(),
panel = function(x,y,...){
panel.xyplot(x,y,...)
})+
layer(panel.smoother(y ~ x, method = "lm"), style =1)+
layer(panel.smoother(y ~ poly(x, 3), method = "lm"), style = 2)+
layer(panel.smoother(y ~ x, span = 0.9),style=3) +
layer(panel.smoother(y ~ log(x), method = "lm"), style = 4)
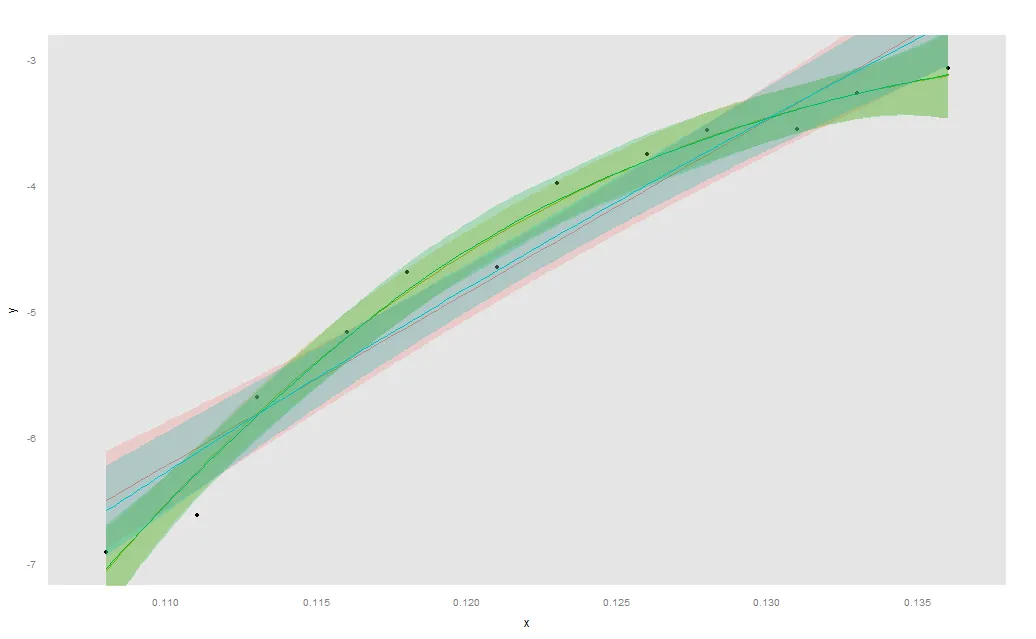
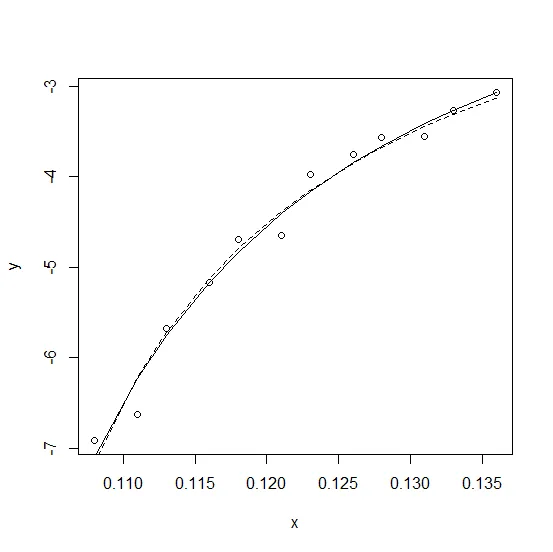
看起来你需要一个立方模型。
summary(lm(y~poly(x,3),data=dat))
Residual standard error: 0.1966 on 8 degrees of freedom
Multiple R-squared: 0.9831, Adjusted R-squared: 0.9767
F-statistic: 154.8 on 3 and 8 DF, p-value: 2.013e-07
rgp包进行符号回归吗?如果您提供一些样本数据,我们可以尝试一下。更多细节请参见:http://www.rsymbolic.org/projects/rgp/wiki/Symbolic_Regression - Ben