我注意到这个问题很多。也就是说,如何将具有列表的列拆分为多行?我看到它被称为爆炸。以下是一些链接:
所以我写了一个能够实现它的函数。
def explode(df, columns):
idx = np.repeat(df.index, df[columns[0]].str.len())
a = df.T.reindex_axis(columns).values
concat = np.concatenate([np.concatenate(a[i]) for i in range(a.shape[0])])
p = pd.DataFrame(concat.reshape(a.shape[0], -1).T, idx, columns)
return pd.concat([df.drop(columns, axis=1), p], axis=1).reset_index(drop=True)
但在使用之前,我们需要在一列中使用列表(或可迭代对象)。
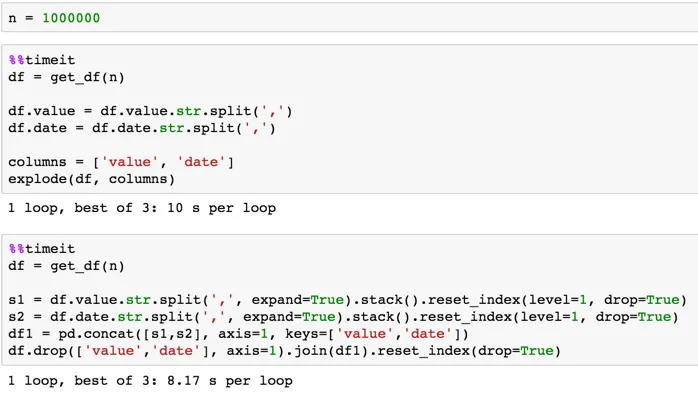
设置
df = pd.DataFrame([['aa', 'assets', '100,200', '20121231,20131231'],
['bb', 'liabilities', '50,50', '20141231,20131231']],
columns=['ticker', 'account', 'value', 'date'])
df
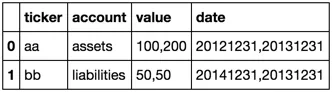
分割 value 和 date 列:
df.value = df.value.str.split(',')
df.date = df.date.str.split(',')
df
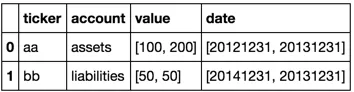
现在我们可以分别或同时展开任一列。
解决方案
explode(df, ['value','date'])
计时
我从@jezrael的计时中删除了strip,因为我无法有效地将其添加到我的计时中。对于这个问题来说,这是必要的一步,因为OP在逗号后字符串中有空格。我旨在提供一种通用的方式来展开一个已经包含可迭代对象的列,我认为我已经做到了。
代码
def get_df(n=1):
return pd.DataFrame([['aa', 'assets', '100,200,200', '20121231,20131231,20131231'],
['bb', 'liabilities', '50,50', '20141231,20131231']] * n,
columns=['ticker', 'account', 'value', 'date'])
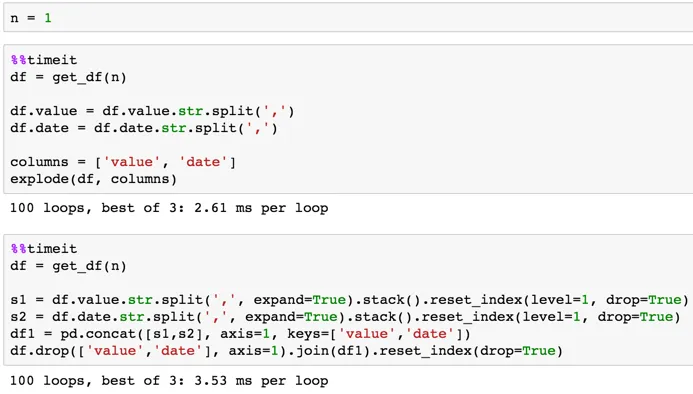
小的2行示例
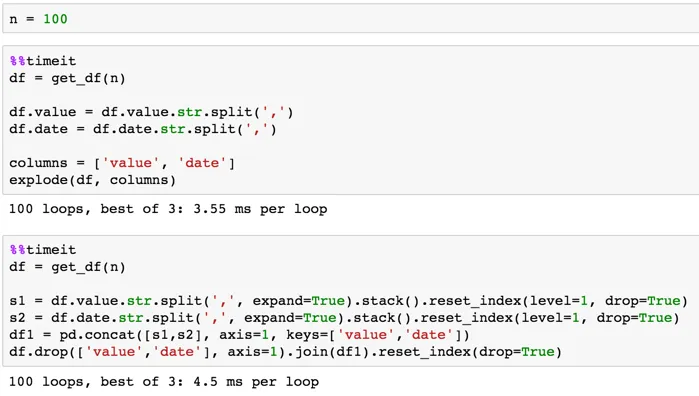
中等规模200行示例
大型 2,000,000 行样本